
Redis 운영 관리
너무 유용해서 정리 중
관련 책 : www.kyobobook.co.kr/product/detailViewKor.laf?ejkGb=KOR&mallGb=KOR&barcode=9788968486814
Redis 운영 관리 - 교보문고
『Redis 운영 관리』는 Redis의 특징과 함께 어떻게 운영하고 관리해야 하는지를 알아보는 책이다. Redis 복제 모델과 복제시 주의해야 할 사항을 학습한다. 저자는 현장에서 얻은 노하우와 실무 팁
www.kyobobook.co.kr
1. Redis의 이해

- 문서 : redis.io/
- 소스 : github.com/redis/redis
- 커맨드 : redis.io/commands
Redis의 주요 특징
- key-value 스토어 : 단순 스트링에 대한 Key/Value 구조를 지원한다.
- 컬렉션 지원 : List, Set, Sorted Set, Hash 등의 자료구조를 지원함
- Pub/Sub 지원 : Publish/Subscribe 모델을 지원한다 (서버간의 통지에 유용함)
- 디스크 저장 (Persistent Layer) :
- 현재 메모리 상태의 스냅샷을 남기는 기능 'RDB' / 지금까지 실행된 업데이트 관련 명령어의 집합 'AOF'
- RDB : 메모리 내용을 저장하는 기능 외에는 아무것도 지원하지 않는다. (데이터베이스가 아니다)
- AOF (Append Only File) : set / del 등의 업데이트 관련 명령어를 그대로 기록함
- 복제 (replication) : 다른 노드에서 해당 내용을 복제할 수 잇는 마스터/슬레이브 구조를 지원
- 빠른 속도 : 이상의 기능을 지원하면서도 초당 100,000 QPS (Queries Per Second) 수준의 높은 성능을 자랑
Redis와 Memcached 비교
| 기능 | Redis | Memcached |
| 속도 | 초당 100,000QPS 이상 | 초당 100,000QPS 이상 |
| 자료구조 | Key-Value, List, Hash, Set, Sorted Set | Key-Value |
| 안정성 | 특성을 잘못 이해할 경우 프로세스 장애 발생 | 장애 거의 없음 |
| 응답 속도의 균일성 | 균일성이 떨어질 수 있음 | 전체적으로 균일 |
Memcached에 저장소의 개념이 추가된 것이 Redis
저장소의 개념 == [RDB, AOF, Replication]
응답속도의 균일 성부분이 문제가 되는 이유 : 두개의 메모리 할당 구조가 다르기 때문
- Redis : jemalloc - free > 메모리 프래그멘테이션(fregmentation) 할당 비용 때문에 응답 속도가 느려진다.
- Memcached : slab 할당자
slab 할당자
내부 단편화 문제를 해결하기 위함 (page 단위 4kb (4096byte) - 할당 받으려는 것 16바이트(16byte) = 4080byte 낭비)
솔루션
- 자주 쓰는 메모리 패턴을 정의한 후 미리 할당
- 해당 페턴에 대한 메모리 할당 요청이 있으면 메모리 할당
- 해당 패턴으로 메모리를 해제하면 우선 그대로 유지 (또 다시 해당 패턴으로 할당 요청을 할 가능성이 높음)
kmem_cache_s 구조체 : 하나의 캐시를 나타냄
keme_list3 구조체 : kmem_cache_s들의 모음. slab 관리
슬랩은 사용자에게 할당할 object들이 저장되어있는 풀구조이다.
커널이 시스템을 초기화 할 때 kmem_cache_init 함수를 통해 자주 사용되는 커널의 오브젝트들의 크기를 고려해 사용목적에 따라 캐시를 생성한다. 32, 64, 128, 256, 512, 1,024, 2,048, 4,096, 8,192, 16,384, 32,768, 65,536, 131,072 byte (페이지 단위 관리보다 내부 단편화를 줄일 수 있다)
2. Redis 운영과 관리
핵심 1 : Redis는 싱글 스레드다
싱글 스레드이기때문에 시간이 오래 걸리는 Redis 명령을 호출하면, 명령을 처리하는 동안에는 Redis가 다른 클라이언트의 요청을 처리할 수 없다.
1. 서버에서는 keys 명령을 사용하지 말자
keys 명령 : 원하는 패턴에 매칭되는 키들을 가져오는 명령어이다.
그러나 이걸 사용하면 장애로 이어질 가능성이 높다. 데이터 양이 늘어날 수록 해당 명령의 속도가 느려진다. 실제로 Redis 매뉴얼에 쓰지 말라고 되어있다.
KEYS – Redis
Returns all keys matching pattern. While the time complexity for this operation is O(N), the constant times are fairly low. For example, Redis running on an entry level laptop can scan a 1 million key database in 40 milliseconds. Warning: consider KEYS as
redis.io
Warning
: consider KEYS as a command that should only be used in production environments with extreme care. It may ruin performance when it is executed against large databases. This command is intended for debugging and special operations, such as changing your keyspace layout. Don't use KEYS in your regular application code. If you're looking for a way to find keys in a subset of your keyspace, consider using SCAN or SETS.
디버깅이나 스페셜한 명령어(keyspace layout 변경하기)로 의도된 것이라 보통의 어플리케이션 코드에서는 사용하면 안된다. 웬만하면 SCAN이나 SETS 명령어를 사용하는걸 고려해보아라.
모든 Key를 대상으로하는 명령어라서 그렇다.
2. flushall/flushdb 명령을 주의하자
db : 가상의 공간을 분리할 수 있는 개념
- flushdb: db하나의 내용을 통째로 지우는 것
- flushall : 모든 db의 내용을 모두 지우는 것
flushall 명령은 전체 데이터를 다 지우며 keys명령처럼 많은 시간이 필요하다 (memcached는 순식간에 모든 데이터가 지워진다) - 동작방식이 다르다
아이템 개수에 비례해서 시간이 걸린다
실제 데이터를 일일히 삭제하는 로직으로 구현이 되어있다 : 지우는 속도가 O(n)
Memecached의 flush_all이 빠른 이유
Memcached에서는 실제로 데이터를 삭제하지 않는다.
해당 명령어가 실행된 시간만 기록하고, 이보다 이전에 저장된 key는 get명령을 통해서 접근할 때 없다고하면서 실제로는 지운다. (oldest_live 플래그만 세팅 : 이보다 먼저 생성된 key는 없다)
핵심2: Redis Persistent
Reids Persistent : Redis 데이터를 디스크로 저장할 수 있다 > 디스크에 저장된 데이터 기반으로 복구가 가능하다
1. RDB
현재 메모리에 대한 덤프를 생성하는 기능.
fork를 이용해서 자식 프로세스를 생성한다. > 현재 메모리 상태가 복제된 자식프로세스를 기반으로 데이터를 저장한다 (지속적인 서비스가 가능하다) - 근데 이렇게 하면 최악의 상황에 메모리가 2배가 필요할 것 같다.
- SAVE : 모든 작업을 멈추고 현재 메모리 상태에 대한 RDB파일 생성 : 싱글 스레드 이므로 아무 작업도 수행할 수 없음
- BGSAVE : 백그라운드 SAVE : fork 작업을 통해 자식 프로세스에서 파일을 저장한다.
#redis.conf
dbfilename dump.rdb
2. AOF
AOF : Append Only File
현재 수행해야 할 명령을 미리 저장해두고, 장애가 발생하면 AOF 기반으로 복구
1. 클라이언트가 Redis에 업데이트 관련 명령 요청
2. Redis가 해당 명령을 AOF에 저장
3. 파일 쓰기가 완료되면 실제로 해당 명령을 실행해서 메모리의 내용을 변경함.
AOF는 기본적으로 사용안함으로 되어있어 변경해주어야한다.
#redis.conf
appendonly yes # default no
appendfilename appendonly.aof # 파일이름 설정
appendfsync everysec # 디스크 동기화를 얼마나 자주할 것인가 (always, everysec, no)
AOF와 RDB의 우선순위 : 최신 데이터를 더 많이 가진 파일 - AOF
RDB는 스냅샷인 반면, AOF는 매 작업마다 디스크에 기록을 남겨서 모든 데이터가 남아있다.
참고 : 레디스 프로토콜
*키워드개수\r\n
[키워드개수만큼 반복]
$키워드크기\r\n
키워드\r\n
3. Redis가 메모리를 두배로 사용하는 문제
장애 원인 : RDB저장시 fork를 사용하기 때문에.
COW (Copy on Write) : 실제로 변경이 발생한 부분만 차후에 복사한다. (그러나 redis는 부분 write가 많다)
참고 : redisgate.kr/redis/configuration/copy-on-write.php
Redis Copy-on-Write
copy-on-write Redis Copy-on-Write 분석 Redis Copy-on-Write 분석 개요 槪要 Outline 레디스 서버의 메모리 사용량은 실 데이터 크기에 관리 메모리(overhead)를 더해야 한다. 그리고 Copy-on-Write로 인한 추가 메모
redisgate.kr
참고 : 대용량 메모리와 Redis
Redis는 싱글 스레드임 : 멀티 코어를 활용하기 위해 여러 개의 Redis 서버를 한 서버에 띄우는 것이 성능 면에서 좋다.
Core4개 + 메모리 32GB 장비 : 프로세스별로 6G 할당하기
- 평상시 : 6 + 6 + 6 + 6 = 24GB
- fork 복제시 : 6 + 6 + 6 + 6 + (6 = 자식) = 32GB
4. Redis장애 : Read 성공 Write 실패
Redis 기본 설정 : RDB저장 실패 => 장비 이상으로 판단 => Write 명령처리하지 않음
lastbgsave_status = REDIS_ERR : Write 관련 요청 모두 무시
Heartbeat체크는 읽기 관련 명령을 이용해 검사하기 때문에 문제 발생 가능.
RDB 생성 실패의 경우
- RDB를 저장할 수 있을 정도의 디스크 여유 공간이 없는 경우
- 실제 디스크가 고장 난 경우
- 메모리 부족으로 인해 자식 프로세스를 생성하지 못한 경우
- 누군가 강제적으로 자식 프로세스를 종료시킨 경우
해결 방법
1) 해당 상황이 맞는지 확인하기 : set 명령어 사용
2) info 명령어 사용 : rdb_last_bg_save_status:ok 인지 확인
3) 정책 결정 : config set stop-writes-on-bgsave-error no
3. Redis 복제
1. Redis 복제 모델
redis는 마스터 / 슬레이브 형태의 복제 모델 제공
-> 이때 슬레이브가 다른 장비의 마스터로도 동작할 수 있게도 할 수 있음 (M-S-S)
1. 명령어 사용 : slaveof <ip> <port>
2. redis.conf 수정 : slaveof <master ip> <master port>
redis-cli로 접속 후 info 명령어 혹은 info replication 명령어를 사용한다.


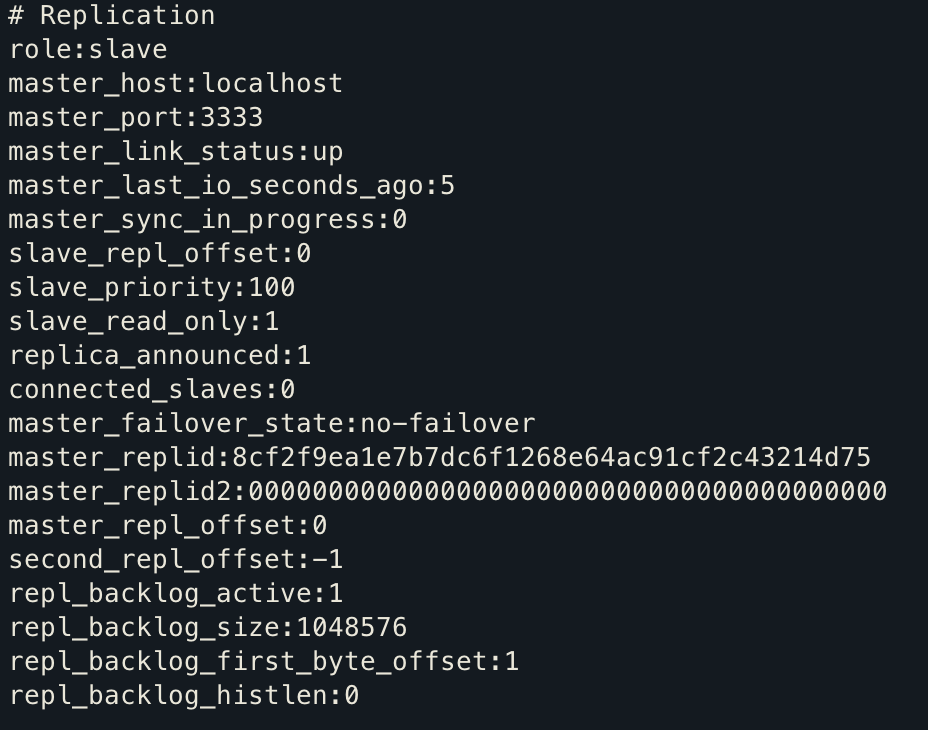

2. Redis 복제 과정
1. slave에서 slaveof 명령어를 이용해 마스터 서버를 설정한다.
2. 마스터 서버가 설정되면 replicationCron에서 현재 상태에 따라 connectWithMaster를 호출한다.
3. 마스터는 복제를 위해 RDB를 생성한 후 슬레이브에 전송한다.
4. 슬레이브는 RDB를 로드하고, 나머지 차이에 대한 명령을 마스터에서 전달받아 복제를 완료한다.
RDB 기준 복제 순서 (full synchronization)
1. 마스터는 자식 프로세스를 시작해 백그라운드로 RDB파일에 데이터를 저장합니다.
2. 데이터를 저장하는 동안 마스터에 새로 들어온 명령들은 처리 후 복제버퍼에 저장됩니다.
3. RDB 파일 저장이 완료되면, 마스터는 파일을 복제서버에게 전송합니다.
4. 복제서버는 파일을 받아 디스크에 저장하고, 메모리로 로드합니다.
5. 마스터는 복제버퍼에 저장된 명령을 복제서버에게 전송합니다.
이때 복제중 끊어지게 되면 backlog-buffer에 데이터가 저장된다. 이후 다시 연결되었을때 이 buffer에서부터 동기화가 이루어진다.
만약 buffer가 넘쳤을때는 full synchronization을 진행한다
3. Redis 복제 사용시 주의 사항
주의점 1. slaveof no one을 기억하자
슬레이브는 마스터의 상태를 지속적으로 감시하면서 바뀌는 내용을 계속 전달받는다.
- 연결 상태 이상이 생기는 경우 : 재 연결이 되면 rsync
- 마스터에 장애가 발생하여 마스터에 데이터가 없는경우 : 슬레이브의 모든 내용이 사라진다.
슬레이브 복제를 진행할 때 emptyDb() 호출로, 현재 자신(슬레이브)의 데이터를 모두 삭제하고 마스터와의 싱크를 맞추려하기 때문이다.
slaveof no one : 더이상 슬레이브로 동작하지 않도록 설정하는 것
주의점 2. 복제 시에 무조건 RDB를 백그라운드로 생성한다는 것을 주의하자
RDB를 사용한다 == 메모리를 두배로 사용할 가능성이 있다. > 설정을 꺼둠
그치만 복제를 사용한다는 것 자체가 fork를 사용해서 RDB를 생성한다는 것 : 하나의 프로세스가 너무 많은 메모리를 사용하지 않도록 나누는 과정이 필요하다.
4. Redis 복제를 이용한 실시간 마이그레이션
1. 데이터 이전을 위한 새로운 redis 인스턴스 실행
2. 새로운 Redis 인스턴스를 기존 마스터의 슬레이브로 설정 (slaveof) - 복제 완료
3. 새로운 장비의 slave-read-only 설정을 끈다.
4. 클라이언트들이 새로운 redis 인스턴스를 마스터로 인식하도록 설정을 바꾼다.
5. slave no one 명령어 : 기존 마스터와의 연결 종료 (완전한 마이그레이션 이후)
6. 기존 장비 제거
4. Redis HA와 Sentinel
1. Redis HA와 Sentinel 구성
redis master에 장애가 발생하면 sentinel은 슬레이브 중 한대를 선택해서 마스터로 승격시킨다 (내부적으로 투표과정을 거친다)
이때 sentinel이 client에 pub/sub으로 master 변경을 통지한다.
- client(sub) -> sentinel(pub)
2. Sentinel이 장애를 판별하는 방법
기본 : PING 명령어의 응답을 활용해서 판단함. (PONG이 안와도 바로 장애로 판단하지는 않는다)
- SDOWN : Subjectively Down : 해당 서버의 장애를 주관적으로 판단
- ODOWN : Objectively Down : 해당 서버의 장애를 객관적으로 판단 -> 진짜 장애 : Failover 진행한다.
sentinel이 여러대 있을 때 Quorum(쿼럼) 값 이상의 센티널에서 SDOWN으로 판단해야 ODOWN이 된다.
- 주로 Sentinel 장비 수를 홀수로
- 쿼럼 값을 해당 장비수의 과반으로 설정하는 것이 좋다
> 대부분의 설명에서 Sentinel을 3대를 띄우고 쿼럼 값을 2정도로 주는 것으로 얘기를 하긴 한다.
SDOWN 판별 : 해당 서버의 last_avail_time과 현재 시간의 차이가 설정된 down_after_period 값보다 클 때
ODOWN 판별 : SDOWN일 경우에만 쿼럼 값을 체크하며, 이 이상일때 ODOWN
3. Sentinel이 마스터로 승격할 슬레이브를 선택하는 방법
sentinelSelectSlave 함수로 결정
1. SDOWN, ODOWN, DISCONNECT 된 상태의 슬레이브는 제외
2. last_avail_time이 info_validity_time 보다 작으면 제외
3. info_refresh 값이 info_validity_time 보다 작으면 제외
4. master_link_down_time 이 max_master_down_time 보다 크면 제외
5. 남은 후보들 중에서 slave_priority가 높은 슬레이브가 우선적으로 선택
slave_priorirty 값은 redis.conf 파일을 조정하여 선출시의 가중치에 영향을 줄 수 있다.
- 0으로 설정하면 해당 슬레이브는 절대로 마스터 승격이 안된다.
4. Sentinel 설정과 사용
# sentinel monitor <클러스터 명> <마스터 IP> <마스터 Port> <쿼럼값>
sentinel monitor resque 127.0.0.1 2001 2
# 다운으로 인식하는 시간
# sentinel down-after-milliseconds <클러스터 명> <시간 miliseconds>
sentinel down-after-milliseconds resque 3000
# sentinel failover-timeout <클러스터 명> <시간 miliseconds>
sentinel failover-timeout resque 900000
# sentinel can-failover <클러스터 명>
sentinel can-failover resque yes # failover 여부 설정
# 마스터 승격후 몇개의 슬레이브가 싱크를 해야 클라이언트에 알려줄 것인지
# sentinel parallel-syncs <클러스터 명> <sync할 slave 숫자>
sentinel parallel-syncs resque 1 psubscribe 명령을 이용해 통지를 받는다. (pub/sub)
+switch-master 감지
<클러스터 명> <이전 마스터 IP> <이전 마스터 Port> <새 마스터 IP> <새 마스터 Port>
5. Redis 모니터링
python 스크립트 : info 명령어를 활용한 스크립트. (python-redis 모듈)
Percona Cacti 플러그인 : www.percona.com/doc/percona-monitoring-plugins/LATEST/cacti/redis-templates.html
Redis-stat : github.com/junegunn/redis-stat
redmon : github.com/steelThread/redmon
추가 참고하기 좋은 사이트 - redisgate.kr/redisgate/ent/ent_intro.php
Redis-Enterprise Introduction
ent_intro 레디스 엔터프라이즈 레디스 엔터프라이즈 서버의 주요 기능 I. Redis + SQL : 데이터 활용 획기적 향상 II. Active-Active 이중화 : 진정한 고가용성을 실현 III. 메모리 한계 극복 IV. 기타 추
redisgate.kr
'Dev Book Review' 카테고리의 다른 글
| [서평] Do it 지옥에서 온 문서관리자 깃&깃허브 입문 (0) | 2019.12.30 |
|---|---|
| [객체지향의 사실과 오해] 2장 : 이상한 나라의 객체 (0) | 2019.10.17 |
| [객체지향의 사실과 오해] 1장 : 협력하는 객체들의 공동체 (0) | 2019.10.14 |



댓글
Comments