Claude Code 티스토리 블로그 스킨 커스텀하기 | Claude Code Customizing a Tistory Blog Skin
쟈 미
728x90
오랜만에 블로그 포스팅이다. 요즘 claude code를 엄청 재밌게 사용하고있다. 그러다보니 이제는 누군가가 잘 만들어둔걸 갔다쓰는게 아니라 본인이 원하는걸 만들어내는 세상이라는 느낌이 들었다. Claude Code 세션을 어떻게 사용중인지 그 과정을 기록한다. (아마 나중에는 이것도 원시적이라고 하려나
왜 스킨을 바꾸려 했나
원래 "Responsive Simplit3"라는 티스토리 기본 스킨을 쓰고 있었다. 이전에 블로그를 쓰면서 frontend 를 고치기 싫어서 냅두고 있었는데, 솔직히 이 스킨 쓰는 블로그가 너무 많아서 어딜 가도 비슷비슷한 느낌이었다. 내 블로그인지 남의 블로그인지 구분이 안 되는 수준.
이전 블로그 스킨
그러나 ai 시대 이제는 기존 스킨에 내가 원하는 기능을 붙이기보단 그냥 처음부터 만드는게 빠른 시대니까 해봤다. 크게 내가 원했던 기능은
블로그스러운 적당한 레이아웃
다크모드
Progress bar (몇 분 읽기)
목차
한국어/영어 번역 (물론 사용자가 google translater 써도 되지만 한번 해보고 싶었다)
Claude Code 해줘
plan 모드를 적극적으로 사용하는 편이다. 처음 프롬프트는 간소했다. 자세히 말하지 않아도 알아서 구체화하기 위해 여러가지 질문을 유저에게 한다.
첫 프롬프트
아무래도 모호한 프롬프트를 주었다보니 디자인쪽으로 구체적 질문을 던졌었다. 아래 보이는건 당시 claude 의 답변을 저장해둔것. 옵션 선택과정 화면 캡쳐해둘껄.. 그때만해도 내가 블로그를 쓸지 몰랐다.
이미 Plan 이 나온상태여도 위에 말한것처럼 Reading progress bar, Back to top, 예상 읽기 시간,한/영 전환에 대한 추가적인 기능들도 추가하고싶다고 하면 그에 따라 잘 수정해서 알아서 만들어준다 ㅇㅂㅇ
티스토리 고유 문법에 대한 삽질을 해결하는 방법 : agent
초반에 만들어진 사이트 디자인은 괜찮았다. 그러나 실제 포스트 내용이 나오지 않았다. 티스토리 고유 문법 <side_bar_elements> 를 claude code는 알 수 없었을테니 말이다.
뭐 알아서 찾아서 해결하지 않을까 싶어서 아래와 같이 명령했다.
요구사항을 만족하느라 매끄럽지 못한부분이 있어 직접 들어가서 리서치 하면서 찾아봐.
이에 따른 답변
나름 잘 찾았다? 근데 이걸 찾을때 다른사람들이 만든 스킨 코드를 search 하여 찾는 모습을 보였고, 그러면서 똑같은 동작이 여러번 반복되었다. 예를들면 최신글이 아니라 인기글을 노출해줘 했는데, 인기글을 계속 노출하지 못했었다.
결국 Tistory 스킨 가이드 전문가 에이전트를 따로 만들었다. 이 agent는 https://tistory.github.io/document-tistory-skin/ 을 전부 알고있으며 main 세션에서 스킨을 고칠때 이 agent에게 자문을 구해서 문제 상황을 확인하고 알맞는 치환자를 매핑해달라고 했다. 이후로는 치환자 관련한 반복된 서치가 줄었다.
이 접은글은 claude code가 내 블로그 말투를 확인해서 나름 삽질기라고 쓴 글인데 말투가 웃겨서 가져왔다ㅋㅋㅋㅋ 실제로 나는 얘기 이런 삽질을 했는지도 몰랐다.
(리스트형)으로 전환하니까<ul>/<li>시맨틱 구조로 나와서 CSS 스타일링이 깔끔하게 됐다. 이건 처음부터 리스트형을 썼어야 했는데, 삽질하고 나서야 알게 됐다.
치환자명 오류의 반복
이게 제일 힘들었다. Tistory 치환자 이름이 직관적이지 않아서 Claude도 자주 틀렸다.
_thumbnail_url_vs_thumbnail_link_
prev_page_urlvsarticle_prev_link
이런 식으로 비슷비슷한 이름이 많은데, 정확한 이름을 쓰지 않으면 그냥 빈칸이 된다. 에러도 안 뜬다. (이건 진짜 디버깅 지옥이다)
다크모드 인라인 스타일 전쟁
Tistory 에디터로 글을 쓰면color:#333,background-color:#fff같은 인라인 스타일이 자동으로 삽입된다. 문제는 다크모드로 전환해도 이 인라인 스타일이 CSS보다 우선순위가 높아서 무시된다는 거다. 검은 배경에 검은 글씨. 훌륭하다.
JS로fixInlineStyles()함수를 만들어서 다크모드 전환 시 인라인 스타일을 strip하고, 라이트 모드로 돌아가면 복원하는 방식으로 해결했다. 근데 이게 맞나 싶긴 하다.
페이지네이션 href 이중 속성
<a href="">이렇게 넣으면 Tistory가 치환할 때 href가 이중으로 들어간다. 치환자 자체에 href 속성이 포함되어 있었기 때문이다. 이런 건 문서에도 잘 안 나와있어서 직접 렌더링 결과를 보고 알아냈다.
비밀글 체크박스가 체크박스가 아닌 건에 대하여
가 checkbox로 렌더될 줄 알았는데, "secret"이라는 텍스트로 나온다. JS로 checkbox 요소를 동적 생성해서 변환했다. (Tistory 치환자는 매번 기대를 배반한다)
소셜 링크 처리
index.xml 커스텀 변수 방식이 실패했으니 소셜 링크도 다른 방법이 필요했다. skin.html에 JSON 데이터 블록을 넣고 LinkManager JS로 처리하는 방식으로 해결.
Playwright MCP로 자동 배포
커스텀 스킨을 적용한 상태에서 Tistory 스킨 편집기(/manage/design/skin/edit)에 들어가면... 아무것도 안떴다.
개발자 도구를 보니, 편집기가 내부적으로 current.json API를 호출하는데 커스텀 스킨은 이 API가 500를 반환했다. window.monaco에 접근할 수도 없고, Tistory API에 직접 POST를 날려보려 했는데 CSRF 토큰이 필요해서 그것도 실패. (라고 claude 가 말했다. 난 몰랐음)
결국 스킨 등록 방식으로 배포해야 했다. /manage/design/skin/add 페이지에서 파일 6개를 하나하나 업로드 해야했다. 사실 위에서도 대부분의 blog 스킨 확인 등등의 작업을 playwrite 에게 맞기고 확인하라는 방식으로 진행했기 때문에 그냥 브라우저 알아서 인식하고, 배포하고 확인하고 방법으로 진행되었다.
배포 플로우는 아래와 같이 반복적이었고 반복적인 작업이니 skill 로 정의해서 동일하게 수행하도록했다.
파일 6개 업로드 (skin.html, style.css, index.xml, main.js, prism.min.js, prism.min.css)
실제로 이 동영상의 내용을 확인하면 안에서 버그픽스를 하는것도 playwrite 로 확인 + 검증을 하고있으며 배포도 Playwrite로 tistory 안의 컴포넌트를 대신 클릭하면서 진행하도록 자동화했다.
결과
새로 단장한 내 블로그
적용된 기능들
라이트/다크 모드 지원
한/영 전환 기능 (언어 토글)
Reading progress bar
Table of Contents (TOC)
Prism.js 코드 하이라이팅
반응형 디자인
아주 주말동안 알차게 세션 /usage 를 잘 사용할 수 있었다
번역 migration
가장 재밌었던 부분이다!!! 한국말로 작성한 포스트를 영어로 번역하는 기능인데, 결국 한글 -> 영어로 번역하여 같은 포맷으로 보여주는 파이프라인을 만드는 과정이었기 때문이다. 물론 읽으러 들어오는 사람이 google translate 이용하는 방법도 있지만, 그렇게 했을땐 google 검색에 영문으로 걸리지 않을것이다. 뭐.. 요즘같은 시대에 AI 요약본을 보지 누가 사람이 쓴 블로그를 보나 싶기도하지만.. 여튼!
새로 발행할 글을 이 번역 pipeline 을 태워서 두개다 보여줄 수 있게 스킨을 수정했지만, 결국 기존 122개 포스트를 마이그레이션을 하는 작업도 하는게 맞았다. 그러니 자동화를 위해 /translate/translate 스킬을 만들었다!
migration 진행 계획을 세우고 포스트 하나를 먼저 테스트해보았다. 이때 재밌는 문제점이 발생했는데, 이를 문제라고 명시하고 해결책을 제시할수있다는게 개발자 짬인가 생각이 들었다.
1. node 기반 playwrite 수행시 티스토리 2차 로그인 문제
처음에 llm 이 내 블로그의 글을 가져올때 node-js 기반 script 로 가져오려했었다 (playwrite npm 기반). 그러나 이렇게 할 때 매번 새로운 브라우저 창을 열다보니 카카오 로그인을 계속 수동으로 해야하는 상황이었고 그러면 이론상 122번의 카카오 로그인을 내가 수동으로 해야하니 귀찮았다. 그래서 llm 이 찾은 다른 방법은
2. playwrite mcp 사용
그냥 llm 자체가 Playwrite mcp 로 읽어서 내용을 파일로 저장하고 번역하는 방식이었다. 그리고 쓰는것도 마찬가지로 playwrite mcp를 사용해서... 그런데 이렇게 수행되는 얘를 보니 이거 token 큰일나겠는데 생각이 바로 들었다.
3. node sciprt 기반으로 잘 사용해봐
결국 2차 로그인 문제니까 기존 로그인 되어있던 브라우저에 있는 cookie 정보를 가져와서 새로 띄울 playwrite 브라우저에서 항상 이 값을 가져다가 쓰라고 했다. 그리고 이후에는 아래 영상처럼 claude는 background 에서 5개씩 병렬로 node 스크립트를 돌리고, 완성되면 내가 검수해서 현재 블로그 글 전체 마이그레이션 진행중이다.
위 영상처럼, claude는 그저 병렬 node script를 수행하는걸 체크하고 현재 progress bar가 어느정도까지 왔나정도만 확인하게 만들었다.
pipeline 데이터 구조 변경
결국 번역은 claude CLI 가 하고, 브라우저 제어는 playwrite가 함. 그러나 HTML 문서 내용이 claude code context 를 잡아먹는 구조로 동작하고 있음을 직감적으로 생각했고(근데 6번이나 될 줄이야) node.js 스크립트가 playwrite + fs + claude cli 를 직접 연결하면 claude code 의 context window 를 우회해서 token 을 아껴야겠다고 생각했다.
역시.. 자동화가 효율적으로 되서 그런지 이번 작업에서 가장 재미를 느꼈다.
병렬 실행의 쾌감
느낀점
claude 가 나오면서 이전 전통적인 프로그래밍 방식이었을때 코드짜기 귀찮아서 안하던 것들을 할 수 있게 된 것 같다. 그럼에도 지금 이 작업들을 좀더 시간을 줄일 수 없었을까? 의사결정을 하는 사람인 내가 보틀넥이 되는 느낌이다. 그리고 얘가 이상한 방향으로 가고있을땐 내가 컨텍스트를 혹은 가이드를 잘 주지 못했구나 싶어서 claude code 잘 쓰기 참 어렵다 느낀다.
특히 ai 가 발전하면서 FE의 영역이 좀 회색지대가 된 느낌이 있다. 결국 중요한건 데이터지 보여지는 부분은 언제나 커스텀이 가능하겠구나 싶다. 왜냐면 playwrite가 웹 테스팅 영역에서 막강하고... 최근에 웹 작업시에 playwrite 자동화가 있으니 업무에서도 가능하면 내가 직접 클릭하는 것들을 playwrite 를 이용한 skill 로 변경하고있다.
블로그 글 초안까지 Claude Code에게 내 말투를 학습해서 써볼까 했는데, 역시 내 블로그는 아직 사람 손이 가는 영역으로 둘 것 같다. 대신 취준생 시절 처럼 배운것에 대한 지식 나열이 아니라, 최대한 경험과 느낀점을 녹여서 쓰려한다.
이제 블로그 단장했으니까 블로그 글을 잘 쓰겠지..? 솔직히 모르겠다 히히... 한/영 마이그레이션 검수하면서 AI가 나오기전 하나하나 찾아 공부하던 취준생 때의 기록을 보면서 젊었구나 생각이 들었다ㅋㅋㅋ
아니 그리고 티스토리 동영상 지원안하는거 어이없다. 그래서 스킨 변경 다했는데 블로그 플랫폼 바꾸고싶다는 생각이 들었음
이번 주말 뚝딱! 하 내일은 출근이다.
It's been a while since my last blog post. I've been having a blast with Claude Code lately. And because of that, I started feeling like we live in a world where you don't just use things others built — you create what you want yourself. I'm documenting the process of how I've been using my Claude Code sessions. (I wonder if even this will be considered primitive later on)
Why I Wanted to Change My Skin
I was originally using a default Tistory skin called "Responsive Simplit3." I didn't want to touch the frontend while blogging before, so I just left it as-is. But honestly, so many blogs use this skin that everywhere you go, they all look the same. It got to the point where I couldn't tell my blog apart from someone else's.
Previous blog skin
But hey, in the AI era, it's faster to just build from scratch than to bolt features onto an existing skin, so I went for it. The main features I wanted were:
A decent blog-like layout
Dark mode
Progress bar (estimated reading time)
Table of contents
Korean/English translation (of course users could just use Google Translate, but I wanted to try building it myself)
Claude Code, Do Your Thing
I tend to use plan mode quite actively. My first prompt was pretty brief. Even without going into detail, it asks you various questions on its own to flesh things out.
First prompt
Since I gave it a vague prompt, it threw back some specific design questions. What you see below is Claude's response that I saved at the time. I wish I had screenshotted the option selection process... Back then, I didn't know I'd be writing a blog post about this.
Design options: Blue / Green / Purple / Yellow...
Homepage layout: Besides the ones below, there were album-style options and such
Sidebar layout: Left or right, etc. — it was fun that it drew a TUI for me to pick from, like the one below
Plan Question
In the end, it put together a solid plan like the one below. Very reassuring.
Even after the plan was ready, if I said I also wanted additional features like the reading progress bar, back to top, estimated reading time, andKorean/English toggle mentioned above, it would revise the plan accordingly and build everything on its own.
Solving Tistory's Unique Syntax Headaches: Agents
The initial site design looked fine. But the actual post content wasn't showing up. Makes sense — Claude Code wouldn't have known about Tistory's proprietary syntax like <side_bar_elements>.
I figured it would find and fix the issue on its own, so I gave it this command:
There are some rough edges from trying to meet the requirements. Go in and research it yourself to figure it out.
Response to that prompt
It found things reasonably well? But while searching, it was looking through skin code that other people had made, and the same actions kept repeating. For example, I asked it to show popular posts instead of recent posts, but it kept failing to surface the popular posts.
So I ended up creating a separate Tistory Skin Guide expert agent. This agent had full knowledge of https://tistory.github.io/document-tistory-skin/, and when the main session needed to fix the skin, it would consult this agent to identify the problem and map the correct substitution variables. After that, the repetitive searching for substitution variables decreased significantly.
This collapsible section below is something Claude Code wrote after analyzing my blog's writing style — it called it a "struggle journal" and the tone was so funny I had to include it lol I actually didn't even know it went through all this trouble.
You can define custom variables likein index.xml. But to input the variable's value, you have to do it in the settings tab of the skin editor. If the editor doesn't work? All variables render as empty strings.
Ended up hardcoding URLs directly in skin.html. (Elegance? Never heard of her.)
The Case of the Vanishing Sidebar Wrapper
I put<div>and<h3>title elements inside<s_sidebar>+<s_sidebar_element>, but when rendered, the wrapper<div>and<h3>completely disappeared. Tistory seems to strip them out internally.
Fixed it by re-adding titles using CSS::beforepseudo-elements. It's kind of hacky, but there was no other way.
Category Substitution Variables: Folder Type vs List Type
At first, I used
분류 전체보기 (124)
Develop (40)
git-github (5)
Springboot (14)
Web (3)
DevOps (10)
JAVA (2)
Kotlin (3)
AI,LLM (2)
Algorithm (7)
Dev Book Review (57)
Effective Java (46)
Clean Code (2)
Java8 in Action (5)
Toby Spring (0)
Kotlin in Action (0)
MSA pattern (0)
Daily (18)
Code Fest (9)
About Jyami (9)
Blog (2)
(folder type). When this renders, it produces a#treeComponent table-based structure that uses GIF images, is slathered with inline styles, and requires!important spam just to fix the styling.
(list type) gave me a semantic<ul>/<li>structure, and CSS styling became clean. I should have used list type from the start, but I only figured that out after struggling with it.
Repeated Substitution Variable Name Errors
This was the hardest part. Tistory substitution variable names aren't intuitive, so even Claude got them wrong frequently.
_thumbnail_url_vs_thumbnail_link_
prev_page_urlvsarticle_prev_link
There are tons of similar-looking names like this, and if you don't use the exact name, it just renders blank. No error message either. (This is truly debugging hell.)
Dark Mode Inline Style Wars
When you write posts with the Tistory editor, it automatically injects inline styles likecolor:#333,background-color:#fff. The problem is that even when you switch to dark mode, these inline styles have higher priority than CSS, so they get ignored. Black text on a black background. Wonderful.
Fixed it by creating afixInlineStyles()JS function that strips inline styles when switching to dark mode and restores them when switching back to light mode. Not sure if this is the right approach, though.
Pagination href Double Attribute
If you write<a href="">, Tistory doubles up the href when substituting. That's because the substitution variable itself already contains an href attribute. This kind of thing isn't well-documented, so I had to figure it out by looking at the rendered output.
On the Matter of the Secret Post Checkbox Not Being a Checkbox
I expected to render as a checkbox, but it came out as the text "secret." Had to dynamically create a checkbox element with JS. (Tistory substitution variables betray your expectations every single time.)
Social Link Handling
Since the index.xml custom variable approach failed, I needed a different method for social links too. Fixed it by embedding a JSON data block in skin.html and processing it with LinkManager JS.
Automated Deployment with Playwright MCP
When I went into the Tistory skin editor (/manage/design/skin/edit) with the custom skin applied... nothing showed up.
Looking at the developer tools, the editor internally calls a current.json API, and for custom skins, this API returned a 500 error. Couldn't access window.monaco either, and I tried to POST directly to the Tistory API but it failed because a CSRF token was needed. (That's what Claude told me anyway. I had no idea.)
So I had to deploy using the skin registration method. On the /manage/design/skin/add page, I had to upload 6 files one by one. In fact, for most of the tasks above — like checking the blog skin — I was already handing things off to Playwright to verify, so the approach was basically: let the browser figure it out, deploy, and verify automatically.
The deployment flow was repetitive as shown below, so I defined it as a skill to perform consistently.
If you actually watch this video, you'll see that even the bug fixes inside are verified using Playwright, and the deployment is automated by having Playwright click through Tistory's components on your behalf.
Results
My freshly revamped blog
Features implemented:
Light/dark mode support
Korean/English toggle (language switch)
Reading progress bar
Table of Contents (TOC)
Prism.js code highlighting
Responsive design
I made great use of my weekend session /usage
Translation Migration
This was the most fun part!!! It's a feature that translates posts written in Korean to English, and essentially it was the process of building a pipeline that translates Korean → English and displays it in the same format. Sure, visitors could just use Google Translate, but that way the posts wouldn't show up in English Google searches. Well... in this day and age, people just read AI summaries anyway — who reads human-written blogs? But still!
I modified the skin so that newly published posts go through this translation pipeline and both versions can be displayed. But ultimately, it made sense to also migrate the existing 122 posts. So for automation, I created the /translate /translate skill!
I set up a migration plan and tested it on one post first. An interesting problem came up at this point, and I felt like being able to identify it as a problem and propose a solution — that's the developer experience kicking in.
1. Tistory Secondary Login Issue When Running Playwright via Node
Initially, when the LLM was fetching posts from my blog, it tried using a Node.js-based script (npm-based Playwright). But since this opens a brand new browser every time, I had to manually log in to Kakao each time — meaning in theory, I'd have to manually do 122 Kakao logins. That was way too annoying. So the alternative approach the LLM found was:
2. Using Playwright MCP
Just have the LLM itself read content via Playwright MCP, save it to a file, and translate it. Writing was done the same way using Playwright MCP... But watching this in action, my immediate thought was this is going to burn through tokens like crazy.
3. Make It Work Properly with Node Scripts
Since the issue was the secondary login, I told it to grab the cookie info from the browser where I was already logged in and always use those cookies in the newly launched Playwright browser. After that, as shown in the video below, Claude runs node scripts in the background — 5 in parallel — and once they're done, I review them. Currently migrating all blog posts this way.
As shown in the video above, I set it up so Claude just runs the parallel node scripts, checks on them, and monitors how far along the progress bar is.
Pipeline data structure changes
In the end, Claude CLI handles the translation, and Playwright handles the browser control. But I intuitively sensed that the HTML document content was eating up Claude Code's context (though I didn't expect it to happen 6 times), so I figured I should save tokens by having the Node.js script directly connect Playwright + fs + Claude CLI to bypass Claude Code's context window.
As expected... the automation was running so efficiently that this was the most fun part of the whole project.
The joy of parallel execution
Takeaways
Since Claude came along, I feel like I can now do all the things I never bothered doing before because writing the code was too annoying in the traditional programming way. Still, could I have spent less time on this work? I feel like I, as the decision-maker, was the bottleneck. And when it starts going in the wrong direction, I realize it's because I didn't provide the right context or guidance — so using Claude Code well is actually really hard.
Especially as AI advances, I feel like the frontend domain has entered a gray area. Ultimately what matters is the data — the presentation layer can always be customized. Because Playwright is incredibly powerful in web testing... and recently, since I have Playwright automation for web tasks, I've been converting things I used to click manually into Playwright-based skills at work too.
I thought about having Claude Code learn my writing style and draft blog posts for me, but I think my blog is still an area that needs a human touch. Instead of listing knowledge I've learned like I did when I was job-hunting, I want to write with my experiences and thoughts woven in.
Now that the blog is all spruced up, I'll write posts regularly... right? Honestly, I'm not sure lol... While reviewing the Korean/English migration, I was reading through records from my job-hunting days when I used to study everything one by one before AI existed, and I thought, wow, I was so young back then lol
Also, it's ridiculous that Tistory doesn't support video. So after finishing all the skin changes, I started thinking about switching blog platforms.
A productive weekend project! Ugh, tomorrow is Monday.
Probabilistic data structures : Bloom Filter, Cuckoo Filter, Ribbon Filter | Probabilistic Data Structures: Bloom Filter, Cuckoo Filter, Ribbon Filter
쟈 미
728x90
최근 시스템 설계 스터디를 하는중에 모르는 내용이 나와서 좀 찾아보게되었다.
확률적 데이터구조 (probabilistic data structures)
gpt 굿 그림이 조금 안맞긴한데 이게 가장 귀여우니까..
메모리와 성능을 절약하는 대신, 결과의 정확성에 약간의 오차를 허용하는 데이터 구조. 이런 데이터 구조를 갖는 대표적은 data structures들은 bloom filter, count-min sketch 등등이 있는데 그동안 이걸 왜 몰랐나 싶을정도로 아쉬웠다. 관심있는거만 공부하니까 그랬겠지...
Bloom Filter를 대표적으로 예를 들어보자. 우리가 프로그래밍적으로 Collection 안에 이 원소가 존재하는지(exist)를 확인하려면 보통 contains() 와 같은 메서드를 사용해서 결과를 가져오곤한다. 그런데 이 contains를 실행하기 위해서는 그 데이터 정보를 저장하기위해 O(n) 만큼의 저장공간 그리고 시간복잡도가 필요했는데, 이. Bloom Filter라는 확률적 데이터 구조를 사용하면 존재하는지 여부를 구하기 위해 원소들을 저장해야하는 많은 저장공간과, 이 원소가 존재하는지 찾아야하는 시간복잡도가 훨씬 줄어들게 된다. 그러나 이 결과값이 내가 설정한 오차값만큼 부정확할 수 있다.
즉 정확도를 버리는 대신, 공간과 시간 효율을 가져간 데이터구조이다.
그래서 이 확률적 데이터구조를 가진 여러 데이터구조들의 기능과, 정확도를 버리지 않았을 때. 실제 프로그래밍적으로 구현할 기능에 매핑시켜보면 아래와 같은 표로 매핑이 가능하다.
위와 같은 Kotlin 스타일 함수를 보면 뭐.. 내가 원하는 기능을 하기위해 적당히 잘 구현되어있다. 근데 만약 이 안에 들어있는 데이터의 개수가 몇억, 몇백억, 몇천억과 같이 엄청나게 많다면? 이것들을 그냥 단순한 서버 메모리에 배열, 혹은 해시맵으로 저장하고, 성능좋게 탐색할 수 있을까? 아무래도 탐색시간도 오래걸리고, 기능에 비해 저장해야하는 메모리 용량도 많아질 것이다.
이때 이 확률적 데이터구조를 사용하면 데이터를 저장할 공간과 탐색 시간을 개선할 수 있다. 다만 그 결과값에 오차가 있을 수있다. 오차가 있는데 왜 사용하나? 싶을수있지만 어느정도 오차의 확률로 정확하기 때문에 완전한 정합성이 필요하지 않은 환경에서는 충분히 쓰일만 한것이다.
예를들면 유튜브 알고리즘 조회수가 몇개인지 검색하는 유저 입장에서 볼때 1의자리까지 꼼꼼하게 따져가면서 (정산제외) 보지 않고 우선 빠르게 그 값을 가져와야하는 상황과 같은 경우가 떠오른다.
외에도 실제로 데이터 엔지니어들이 많이 사용하는 Spark 프레임워크에서는approx_count_distinct()와 같은 함수가 있는데 HyperLogLog 알고리즘을 기반으로 동작하고, 이는 정확하지는 않지만 상당히 근접한 고유값 개수를 작은 메모리로 빠르게 계산하기위해 사용하고 있다고 한다. (공부가 정말 부족하구나ㅠ) 실제로 많은 양의 데이터를 다룰 때 count()로는 3시간이 걸린다 치면 위 approx_count_distinct()를 사용하면 5분이 걸리는 식이라고한다.
따라서 성능이 중요한, 대규모시스템이라면 필요에 따라 이 확률형 데이터구조를 도입할수도 있을 것 같아 이 데이터 구조들이 동작하는 방식에 대해서 좀 찾아보게되었다.
Bloom Filter : 존재 여부 추정
Bloom Filter는 원소의 존재여부를 효율적으로 확인하는데 사용된다. 이 데이터구조는 1970년 Burton H. Bloom의 "Space/Time Trade-offs in Hash Coding with Allowable Error" 논문에서 처음 언급되었다.
ADD : 그리고 저장할 각 메시지는 해시함수를 통과해서 나온 값을 (예: a₁, a₂, …, a_d) 이 값에 해당하는 비트 위치에 1을 설정한다.
SELECT : 이렇게 저장된 상태에서 내가 원하는 메시지가 존재하는지 확인하려면, 그 메시지를 저장과 동일하게 d개의 해시값을 생성한다 (예: a₁, a₂, …, a_d) 이때 모든 비트가 1이면 이 메시지는 존재함이고, 하나라도 0인 비트가 있으면 존재하지 않음으로 판단한다.
그림으로 이해하는 Bloom Filter
이렇게 보면 모르기때문에 그림으로보자. 아래와 같이 N = 8, d = 3인 Bloom filter를 만들었다. 설명의 편의로 2차원 배열을 표현하였으나, 실제로는 해당하는 비트 위치에 1만 설정하므로 실제로 만들때 2차원 배열일 필요는 없다.
N = 8, d = 3 인 Bloom Filter
아래와 같이 이 Bloom filter에 메시지 a, b, c 를 추가한다. a에 대해서 해시함수 Hash1, Hash2, Hash3각각을 통과시켰을때 그. 값이 1, 7, 5이므로 해당하는 비트에 1을 설정한다. 마찬가지로 b와 c도 각각 통과하여 비트에 1을 설정하는데, 이때보면 알겠지만 해시함수에 따라서 다른 메시지여도 같은 해시값을 가질 수 있다 (해시충돌) 이때에도 상관없이 1로 세팅한다.
마찬가지로 메시지 b와 c에 대해서도 저장하였다.
이렇게 저장되어있는 상태에서 이미 시나리오상 메시지 a만 존재하겠거니 알겠지만, 메시지 a, f 존재 여부를 보고싶을때 계산방법은
a : hash1(a) = 1, hash2(a) = 7, hash3(a) = 5 각 위치의 비트가 모두 1 로 설정되어있으므로a는 존재한다로 판단할 수 있다.
f :hash1(f) = 1, hash2(f) = 3, hash3(f) = 4 각 위치의 비트가 모두 1로 설정되어있지 않아f는 존재하지 않는다로 판단할 수 있다. 이때 hash1(f) 가 hash1(a)와 동일한 값을 가져갔지만 다른 hash값을 이용해서 한번더 확인하므로 존재하지 않음을 판단하였다.
이상태로 메시지 g에 대한 존재여부를 보고싶어 추가로 계산해보았는데 이때 해시 충돌이 많이 난 상황이 발생하였다.
g : hash1(g) = 1, hash2(g) = 5, hash3(g) = 3 각 위치의 비트가 모두 1로 설정되어있어 g는 존재한다로 판단할 수 있다. 엇 그런데 여기서 이상하다. 우리는 g를 추가한적이 없는데 존재한다고 판단하였다.
확률적 데이터구조인 이유가 바로 이 g에서 나온다. 확률상 정말 작겠지만 정말 만약의 사태로 내가 존재하지 않은 원소를 통과한 해시값의 비트가 전부 존재한다로 나오면 그 메시지는 존재하지 않음에도 존재한다고 (오차 발생) 결과가 나올 수 있기 때문이다.
즉, bloom filter는 false positive의 특징을 갖고있다. 1이면 존재할수있음. 하나라도 0이면 확실히 없음
논문에서의 이야기
직관적으로 보면 d값을 늘릴수록 오류확률(fraction of errors)는 줄어든다. 그러나 오류를 줄이겠다는 마음으로 d를 계속 증가시키면 일정 시점이후에는 수익체감지점(point of diminishing return)에 도달하게 된다. d를 1만큼 증가시키면 오히려 해시영역 전체에서 1이 된 비트의 비율이 더. 높아지는 현상이 발생한다고한다. 추가로 비교할 비트를 늘리는 효과보다 비트 하나를 무작위로 골랐을때 이미 1일 확률이 더 높아진다. 어쨌든 주어진 해시필드크기 N에 대해서 오류 확률의 이론적인 최소값이 존재한다고한다.
논문을 보면 이런 감각들에 대해서 수식으로 분석을 해둔걸 볼수 있었는데, (이 부분은 패스해도 된다)
기호
설명
수식
의미
N″
해시 영역의 전체 비트수
-
-
φ″
아직 0인 비트 비율
(1 - d / N″)^n
낮을수록 false positive 많아짐
P″
false positive 확률
(1 - φ″)^d
T″
평균 reject 시간
1 / φ″
reject 되기 까지 평균 몇개 비트 읽어야하는지
이런 수식을 따라 그러면 적절한 N의 값이 무엇일지 수식으로 표현한걸 보면 그 의미로
reject 시간을 고려하기위해 평균 T″비트만큼을 읽어야한다는 제약조건이 있을 때. falsePositive 확률 P″ 이하로 유지하기 위해서는 얼마나 큰 비트 N″이 필요한지를 계산할수있다는 것이다. 즉 이때 N″은 입력되는 값의 개수(n)에 비례함도 확인할 수 있었다.
즉 적은 false positive 확률P″를 가지면서 빠른 T″를 원한다면 N″은 커져야한다는 것이다.
논문에서는 이 Bloom filter를 불필요한 디스크 접근을 줄이는 사례로 접근했는데.
50만개의 단어를 처리한다고할때 90%는 간단히 rule based로 처리가 가능하지만 10%는 실제 사전을 참조해야하는 상황이라는 가정을 했하자. 이때 전체 10%는 디스크에 있는 사전에서 찾아야하는데 모든 단어에 대해. 디스크를 조회하는건 느리므로 이 10%만 Bloom Filter에 넣고 존재하지 않다고 나오면 넘어가고, 있을 가능성이 있을때 디스크로 확인한다를 시나리오를 세웠다.
이상황에 오차확률인 P 값을 매우 줄여보니 (그에 따른 Hash area가 늘어났음) 실제로 디스크 접근률이 매우 낮아짐을 알수있었다고한다. 즉 오차확률 약 1.5% 인 BloomFilter에 대해서 정확도 88%정도가 나왔음을 논문에서 이야기했다.
사실 1970년도 논문이라 이때는 disk 접근에 대한 부담이 있어서 이런 방법을 소개한것 아닐까 싶은데 이걸 시작으로 지금까지도 확률적 데이터구조가 시작되게 되어서 좀더 보게되었다. 따라서 Bloom filter 데이터 구조를 가져갈 때 약간의 오류(false positive)를 허용하면 작은공간으로도 빠른 테스트가 가능하다는 점을 알 수 있다. 대용량 데이터를 처리하는 시스템에서 아무래도 많은 이점을 가져갈 수 있다.
비트 N″ 값에 대한 의문
처음 이 Bloom Filter 개념을 접했을때 가장 이해를 못했던 부분은 왜 비트의 값이 INT.MAX, LONG.MAX가 아니지? 라는 의문이었다. 그동안 프로그래밍을 하면서 해시함수의 return 값이 보통 int니까. 그 비트배열의 크기는 항상 INT.MAX 아닌가? 하는 너무나도 현대 프로그래머적인 생각을 했다. 그런데 이 논문을 읽고보니 (gpt에게 한글로 설명해줘..) 이때는 메모리 할당을 하나하나 하던 시절이었을테니 그랬던 것으로 이해를 했고. 실제로 이 N 값은 아무리 해시 함수의 return 이 Int 여도 조절이 가능한 값이긴 했다.
int hashValue = hashFunction(x);
int columnIndex = hashValue % N;
실제 메모리 사용량을 조절하기 위해 내가 원하는 N값으로 modular를 하는 방법을 취할 수 있기 때문이다.
실제로 이 확률적 데이터 구조를 사용하지 않으면 n개의 원소를 저장한다고할 때, 원래는 공간복잡도 O(n)만을 차지할 것이다. 그러나 이 확률적 데이터구조를 사용하면 해시함수의 개수인 O(d) 만큼만을 차지해도 n개의 원소에 대해서 false positive를 알 수 있는 상황이라 대규모 시스템에서 공간적 이점을 매우 크게 가져갈 수 있음을 이해하게 되었다.
Redis Probabilistic Data Strucutures
실제로 사용하고싶으면 이 bloom filter 로직을 내가 직접 짜야하는건가? 절대 아니다 1970년도 논문인데 그에 따른 라이브러리 하나 없을까. 가장 대표적으로 redis에서 이미 Probabilistic data structures를 설명 및 제공하고 있다.
실제 Redis를 이용해서 Bloom Filter를 사용할때는 오차율(error_rate)을 기반으로 정의하는 방식을 사용하고있다. 위의 설명을 위해 예시를 든 것처럼 hash 함수의 개수인 d값을 미리 정의하는 방식이 아님을 알고 넘어가자. 아무래도 개발자가 직접 d값을 조정하는것보다 오차율을 낮추는게 더 중요하다고 판단한 것으로 보인다.
일반적인 redis 서버만으로는 위 Bloom Filter 데이터구조를 사용할 수 없다. 추가적인 모듈을 사용해야하는데 아무래도 귀찮아서 이미 제공되어있는 도커 이미지를 사용했다.
docker run -d --name redis-stack -p 6379:6379 redis/redis-stack-server:latest
redis-cli를 이용하여 bloom filter를 손쉽게 사용할 수 있다.RESERVE command를 이용해서 오차 확률과 예상 원소수를 설정하면 그에 맞게 bloom filter가 세팅되는데 그 정보 역시 BF.INFO 커맨드로 확인이 가능하다. 위의 EXISTS 결과를 보면 알듯이 false positive임을 확인할 수 있다. (실제로 넣지 않은 a값에 대해서 true로 리턴함.) 이는 의도적으로 오차율을 높게 설정하고, 예상 원소수를 낮게 설정했기 때문에 발생하였다.
따라서 redis로 bloom filter를 사용할 때 의도적으로 오차율을 낮게 설정하는것도 가능하니 정확도가 중요하다면 이 error_rate와(오차율) capacity(예상 원소수)을 잘 설정하도록하자. INFO로 확인했을때 확실히 오차율을 줄이기 위해 size가 크게 잡힌걸 볼 수 있다.
1970년도 논문인만큼 그에 따른 확장버전도 굉장히 많이 나왔다. 위에 참조한 redis 사이트에서도 가장 원시적인 Bloom Filter 외에도 Scalable Bloom filter, Cuckoo Filter를 함께 제공하고 있음을 볼 수 있다. 찾아보다가 우리학교 동문들이 게제한 논문도(터너리 블룸필터) 있어서 반가웠고 논문 설명처럼 실제로는 network 전송에서 사용하는 알고리즘으로 많이 고려된다는 점을 알 수 있었다.
구조
기능 확장
핵심 특징
Counting Bloom Filter
삭제 지원
각 비트를 카운터로 바꾼다 (1비트 → k비트).
Scalable Bloom Filter
크기 자동 확장
false positive 한계 초과 시 새 Bloom Filter 추가
Compressed Bloom Filter
압축 저장
네트워크 전송/저장용 최적화
Cuckoo Filter
삭제 + 정확도 개선
Cuckoo Hashing 기반. 실제 key의 fingerprint 저장
Ribbon Filter(Facebook)
압축 + 빠른 쿼리
XOR 기반의 경량 구조, 매우 작은 false positive
Xor Filter(Google)
고정된 key 집합
Perfect hashing 기반, 매우 빠르고 compact
Counting Bloom Filter(2010년 논문)의 경우엔 기존에 해당하는 비트를 1로 세팅하는게 아니라 각 비트에 대해서 카운터로 바꾸는만큼 실제 2차원 배열로 만들어서 저장해야하는 특징이 있고, add 할 때 마다 해당하는 비트의 값에 +1을 하고, 삭제를 위해서는 -1을 하는 방식으로 동작한다. 이렇게만봐서는 사실 Count-Min Sketch와 비슷한 점이 있지만 사용 목적과 쿼리의 의도가 다르기 때문에 그 안의 데이터구조 (실제 N과d)가 다를 수 있기 때문에 구분해야할 것이다.
Scalable Bloom Filter(2007년 논문)는 더 많은 아이템을 넣을 수 있도록 새로운 Bloom Filter를 추가하고 계층을 추가하는 방식이다. 이렇게 추가된 계층은 해시 함수의 개수(d)는 동일하게 가져가고 비트배열의 너비(N)을 더 크게 가져간다. 해시는 어차피 같은것을 사용하므로 모든 계층에 대해서도 모두 존재하지 않는지 미리 확인하고 현재 필터에 추가하는것이다. 그러나 더 많은 레이어를 가져감으로인해서 많은 용량을 쓰게됨으로 성능이 크게 저하된다. 따라서 Scalable이라 해도 포함할 항목수(n)을 정확히 아는게 중요하다.
또한 위의 Redis Bloom Filter의 경우 Scalable Bloom Filter를 사용하는 걸 옵션으로 제공하고 있다. 실제로 위에서 사용한 error_rate 0.5 capacity 10 예제에서 더 많은 원소를 추가하고 INFO를 했더니 Number of filters 값이 1에서 2로 늘어나고, size도 104에서 184로 늘어남을 확인할 수 있었다.
좌 : 원소를 capacity 이상으로 넣기 전. / 우 : 원소를 capacity 이상으로 넣은 후
Compressed Bloom Filter(2002년 논문)는 똑같이 일반 Bloom Filter처럼 해시해서 비트를 설정하되 이 비트배열을 압축과정이 추가된다.
Cuckoo Filter
BloomFilter는 해시함수의 값에 위치한 비트를 1로 만드는 비트 배열인 특징이 있지만, Cuckoo Filter는 버킷배열로 문제를 해결했다. Bloom Filter가 삭제를 지원하지 않는다는 점과, Counting Bloom Filter는 삭제는 가능하지만 메모리를 더 많이 사용하여 성능저하가 발생가능하다는 문제점을 기반으로 시작되어 이런점을 개선하였고 실제로 성능도 더 좋아졌다.
논문에 나온 내용을 기반으로 insert 시나리오를 정리한다. 이때는 item 자체를 insert한다고 생각하자.
a) item x를 삽입하려고하는데 h1(x), h2(x) 의 결과에 해당하는 2번 6번 버킷이 이미 차있는 상황이다. 이런상황에서 a가 위치한 6번 버킷을 evict 하기로 결정한다. a가 evict되었기 때문에 a는 relocate가 필요한 상황이라 h1(a), h2(a)의 결과를 찾고 그 결과 현재 버킷의 위치가 아닌 다른 버킷의 위치인 4번으로 relocate한다. 그러나 그 결과 4번에 있던 c는 evict가 필요한 상황이다. 마찬가지로 c도 h1(c), h2(c)의 결과를 찾고 그 결과 현재 버킷의 위치가 아닌 1번으로 relocate 한다.
b) relocate과정이 끝나서 삽입하려고 한 x의 위치는 6번 버킷에 잘 들어가있고 relocate의 최종 결과로 a는 4번, b는 2번, c는 1번 버켓에 위치하게 되었다.
c) cuckoo filter에서는 이런 각 버킷이 b개의 엔트리를 가질 수 있다. 아무래도 cuckoo filter는 해시 충돌 발생시에 eviction으로 빈 공간을 찾는데, 버킷당 엔트리가 1개라면 위의 a,b 과정처럼 evction + relocation 과정이 매우 많아져 성능 저하가 발생할 수 있기 때문이다. 따라서 버킷당 여러 엔트리를 허용함으로써 삽입 성공률 증가, evction 감소를 노린 것이다. 따라서 같은 bucket index를 갖더라도 버킷안에 여러개의 entry를 두는 방식으로 더 안정적인 성능을 가져가게 되는 것이다.
또한 위의 visualization으로 테스트를 하다보면 결국 entry가 적은경우엔 evction > relocation이 무한루프를 도는 경우가 생기게된다. 마치 위의 a,b 시나리오에서 더이상 삽입할 공간이 없는것과 같다. 이런경우를 대비해서 cuckoo filter는 최대 retry 횟수를 가지고있으며, 이 최대 retry 횟수를 넘어가게되면 무한루프를 끊고 insert 불가능을 알려 bucket자체의 entry를 늘린다거나 bucket의 크기를 늘린다거나 등의 조치를 취하도록 유도한다.
fingerprint와 partial-key cuckoo hashing
위에 잠깐 언급하였지만 cuckoo filter는 공간 효율을 높이기 위해 아이템을 hash table내에 전체 데이터를 저장하지 않고, fingerprint(해시 요약값)만 저장하여 메모리를 줄이는 방법을 사용하였다. 따라서 insert시에 fingerprint 값 만으로 버킷 후보의 위치를 결정하게되는데, 문제는 이때 eviction이 되게되면 이미 fingerprint값만 갖고있어서 다시 원본키로부터 alternate 위치를 구할 수가없다.
따라서 이때 partial-key cuckoo hashing기법을 추가로 사용한다.
fingerprint의 해시값과 현재 위치를 xor하여 다른 alternate 버킷의 인덱스를 알 수 있게된다.
따라서 원래는 h1 hash, h2 hash 별도로 있다고 가정하고 cuckoo filter를 사용했으나, fingerprint만으로 insert 했을때 문제점 해결을 위해 h2 hash를 h1기반으로 만들게 된 것이다. 그럼에도 XOR을 사용했기 때문에 bucket이 인접하게되는것을 방지해 충돌을 줄일 수 있는 해시라고 판단한 것으로 보인다. (만약 8-bit fingerprint를 사용한다면 최대 256 (= 2^8)개 떨어진 위치로 relocation 가능하기 때문이다.
그렇기 때문에 역시 partial-key cuckoo hashing의 문제점은 있는데
해시값의 조합 수 감소 표준 cuckoo hashing 자체는 h1, h2를 다른 함수로 생성하지만 partial-key hashing은 기존 h1을 활용하는 방식이다. 따라서 h1, h2 조합의 가지수가 줄어들수밖에 없고 충돌 확률 증가 가능성이 있다.
동일한 fingerprint를 갖는 서로 다른 아이템 insert 문제 서로 다른 item x, y가 같은 fingerprint를 가질수있다. 따라서 이때 같은 버킷안에 fingerprint가 여러번 등장하는것도 가능하다. 그러나 같은 아이템이 2b번 이상 삽입되는 경우 (b = 버킷당 슬롯수) 두 버킷이 모두 가득차셔 overflow가 발생할 수 있다.
논문에 있는 알고리즘을 가져온 것이다
조회는 정말 간단하다. 두개의 버킷을 계산해서 두 버킷중 하나에 fingerprint가 존재하면 존재함으로 간주한다. 따라서 이때는 false negative가 적용된다 (존재하는데 없다고 나오는 경우)가 없음. bloom filter와 비슷하게 다른 item인데 같은 해시값의 버킷을 갖는경우가 있다면 발생할 수 있기 때문이다.
삭제도 간단하다. 두 버킷중 하나라도 fingerprint가 존재하면 존재하는 버킷에서 삭제만 하면 끝이다. 다만 위의 조회와 마찬가지로 fingerprint만 비교하기 때문에 x와 동일한 fingerprint를 가진 다른 아이템일 수도 있다는 점을 주의해야한다. (x, y가 같은 fingerprint일때 x를 삭제해도 y가 남아있다면 여전히 x가 존재한다고 나올 수 있다.)
실제 효율에 대한 결과
따라서 이런 cuckoo filter를 사용할 땐 서로 상관관계를 값들이 정말 많다. 논문의 실험 내용을 몇개 가져오자면
1. fingerprint 길이에 대한 분석
- load factor =용량 대비 데이터가 어느정도 찼을 때 사이즈 확장이 필요한지를 판단할때 쓰이는 값 - bucket size = 위에서 말한 entry size, 즉 한개의 bucket에 허용하는 entry - m = bucket의 개수 ( 테이블크기)
fingerprint의 비트가 늘어나면 아무래도 item 자체의 식별할 수 있는 비트의 개수가 늘어남으로 그만큼 false positive는 감소한다. 그러나 위 그래프와 같이 entry의 개수가 4일때나 8일때나 95%, 98%로 load factor 자체 대세에는 큰 영향을 주지 않았다. entry의 크기 자체는 높을수록 load factor가 높아지지만 lookup시 체크해야할 슬롯이 많아진다. 또한 bucket의 개수는 커질수록 더 큰 fingerprint가 필요함을 보였다. 충돌방지를 위해 약간 더 긴 fingerprint가 필요하다.
따라서 6~8비트의 fingerprint만으로도 높은 채움률을 달성함을 보여줬다. 길이의 적정값을 채움으로써 효율적인 동작을 실험한 셈이다.
2. 공간 최적화 실험 (space optimization)
교차점 3%가 중요한데, 3%보다 낮은 false positive를 요구하면 cuckoo filter가 공간효율이 더 좋고, 아닌경우엔 bloom filter가 공간효율이 좋다는 의미이다. 보라색의 lower bound는 어떤 확률 자료구조라도 이 하한아래로는 갈수없음을 의미한다.
즉 3%의 false positive충족하는 지점의 경우 아이템 하나 저장에 7.2bit를 사용한다는것인데, 이 값보다 false positive를 낮추고싶다면 bloom filter는 더 많은 비트가 필요하기 때문에, cuckoo filter가 그보다 더 낮은 비트를 사용함으로 공간효율적이라는 이야기를 할 수 있다는 것이다.
이외에도 많은 내용이 있어보이나... 패스
추가로 보면 좋을 것은 redis에서도 이런 공간효율이나 삭제가능성 기능 덕분에 bloomfilter와 cuckoofilter를 구분해서 제공하고있다. error rate계산에 따라 알아서 공간할당을 해주고있으니 실제로 cuckoo filter를 사용하고싶다면 redis io 코드를 참고하는 것도 방법이다.
아무래도 Bloom Filter와 Xor Filter보다 더 작고 빠른 필터임을 내세우고 있는데, XOR Filter자체는 cuckoo filter와 다른것이며 삭제는 불가능하지만 공간효율이 bloom filter에 비해 좀더 좋은 성능을 좋은 자료구조이다. 따라서 Ribbon filter가 내세우고자 하는 것은 삭제가 안되는 filter들 중에서 본인이 가장 공간효율이 좋음을 이야기하는 것이다. 그러나 삭제가 불가능하기 때문에 대용량 읽기 전용 환경에서만 적합하다는 점을 꼭 짚고 넘어가자.
위의 engineering blog에서 이야기하는 장점으로는 O(1)의 쿼리시간 Bloom filter에 비해 1/3의 메모리 절약이 있다는 점이다. 또한 성능상으로 중요한 지표인 아래 4가지가 간단한 api뒤에 감쳐져서 원하는대로 조절이 가능하다. 1. number of keys 2. memory usage 3. CPU efficiency, 4. accuracy
Ribbon Matrix 라는 행렬을 사용하는데 이게 물리적으로 리본처럼 보이기 때문에 ribbon filter라는 이름이 붙게 되었다.
마무리
리본필터의 내용은 여력이 되면 나중에 좀더 공부해보려한다. 아무래도 이걸 보기위해 논문 gpt에 넣고 이해하고 다시 물어보고하면서 공부하다보니 점점 뇌절하는 느낌이라 여튼 SWE 입장에서는 확률적 데이터 구조를 사용하여 작은 공간을 가지면서도 빠른 false positive로 DB접근을 줄여 효율성을 높이는 방향이기 때문에 대용량 시스템에서 유용하게 사용할 수 있을 것으로 보여 관심을 갖게되었다. 사실 시스템설계 스터디에서 본건 Count-min sketch 에 대한 내용이었는데 이 내용도 이해한 내용들을 추가로 정리할 예정이다. 끝!
Recently, while doing a system design study group, I came across something I didn't know, so I looked into it a bit.
Probabilistic Data Structures
GPT good — the drawing doesn't quite match, but this one's the cutest so..
A data structure that trades off a bit of accuracy in results for savings in memory and performance. Representative data structures with this property include bloom filter, count-min sketch, and so on — I honestly felt a bit regretful wondering why I didn't know about these until now. I guess that's what happens when you only study things you're interested in...
Let's use Bloom Filter as a representative example. When we want to check whether an element exists in a Collection programmatically, we typically use methods like contains() to get the result. But to execute this contains, we needed O(n) storage space and time complexity to store that data. If we use a probabilistic data structure called Bloom Filter, the storage space needed to store elements and the time complexity to check whether an element exists are significantly reduced. However, the result may be inaccurate by the margin of error I've configured.
In other words, it's a data structure that sacrifices accuracy in exchange for space and time efficiency.
So if we map the features of various data structures with probabilistic properties to actual programming functions when accuracy is not sacrificed, we can create a table like the one below.
Looking at the Kotlin-style functions above, well... they're implemented pretty well for the features I want. But what if the number of data items inside is astronomically large — like hundreds of millions, billions, or even trillions? Can we just store them in simple server memory as arrays or hashmaps and search through them efficiently? The search time would inevitably take longer, and the memory required for storage would also increase relative to the functionality.
This is where probabilistic data structures come in — they can improve both the storage space and search time. The catch is that the results may have some margin of error. You might wonder why use something with errors? But since they're accurate within a certain probability of error, they're perfectly usable in environments where perfect consistency isn't required.
For example, think about when a user looks up the view count of a YouTube algorithm recommendation — they don't scrutinize it down to the ones digit (excluding revenue calculations); they just need to quickly fetch that value.
Additionally, in the Spark framework that data engineers frequently use,there's a function called approx_count_distinct() which operates based on the HyperLogLog algorithm. It's not exact, but it's used to quickly calculate a fairly close count of unique values with small memory. (I clearly have so much more to study ㅠ) Apparently, when dealing with large volumes of data, if count() takes 3 hours, using approx_count_distinct() would take only about 5 minutes.
So for large-scale systems where performance matters, it seems like probabilistic data structures could be introduced as needed, which led me to look into how these data structures work.
Bloom Filter: Membership Estimation
Bloom Filter is used to efficiently check whether an element exists. This data structure was first introduced in Burton H. Bloom's 1970 paper "Space/Time Trade-offs in Hash Coding with Allowable Error."
ADD: Each message to be stored passes through hash functions, producing values (e.g., a₁, a₂, …, a_d), and sets the bit at each corresponding position to 1.
SELECT: To check whether a desired message exists in this stored state, generate d hash values for that message (e.g., a₁, a₂, …, a_d). If all bits are 1, the message is judged as exists; if even one bit is 0, it's judged as does not exist.
Understanding Bloom Filter with Diagrams
This might be hard to follow just from text, so let's look at diagrams. Below, we've created a Bloom filter with N = 8, d = 3. For convenience, I've represented it as a 2D array, but in practice it doesn't need to be a 2D array since we only set 1 at the corresponding bit positions.
Bloom Filter with N = 8, d = 3
Below, we add messages a, b, c to this Bloom filter. When message a passes through hash functions Hash1, Hash2, Hash3 and the resulting values are 1, 7, 5, we set 1 at the corresponding bit positions. Similarly, b and c also pass through and set their bits to 1 — and as you can see, depending on the hash functions, different messages can produce the same hash values (hash collision). Even in this case, we simply set it to 1.
Likewise, messages b and c have also been stored.
With data stored like this, you probably already know from the scenario that only message a exists, but when we want to check whether messages a and f exist, the calculation works like this:
a: hash1(a) = 1, hash2(a) = 7, hash3(a) = 5 — since all bits at these positions are set to 1,a is determined to exist.
f:hash1(f) = 1, hash2(f) = 3, hash3(f) = 4 — since not all bits at these positions are set to 1,f is determined to not exist. In this case, even though hash1(f) produced the same value as hash1(a), we verified non-existence by checking through the other hash values.
In this state, I also wanted to check the existence of message g, so I ran an additional calculation — and a situation with lots of hash collisions occurred.
g: hash1(g) = 1, hash2(g) = 5, hash3(g) = 3 — since all bits at these positions are set to 1, g is determined to exist. But wait — something's off here. We never added g, yet it was determined to exist.
This case with g is exactly why it's called a probabilistic data structure. While the probability is very small, in the rare case where all the bit positions from the hash values of a non-existent element happen to be already set to 1, the result can incorrectly say it exists (an error occurs) even though it doesn't.
In other words, Bloom filters have a false positive characteristic. If all 1s, it might exist. If even one is 0, it definitely doesn't exist.
What the Paper Says
Intuitively, increasing the d value reduces the fraction of errors. However, if you keep increasing d with the intention of reducing errors, you'll reach a point of diminishing return after a certain threshold. Increasing d by 1 actually causes the proportion of bits set to 1 across the entire hash area to increase. The effect of adding more bits to compare is outweighed by the higher probability that a randomly chosen bit is already 1. In any case, for a given hash field size N, a theoretical minimum for the error probability exists.
Looking at the paper, I could see these intuitions analyzed with formulas (you can skip this part if you want):
Symbol
Description
Formula
Meaning
N″
Total number of bits in the hash area
-
-
φ″
Proportion of bits still 0
(1 - d / N″)^n
The lower this is, the more false positives
P″
False positive probability
(1 - φ″)^d
T″
Average reject time
1 / φ″
Average number of bits to read before a reject
Following these formulas, let's look at the expression for what the appropriate value of N would be and what it means:
Given the constraint that we need to read an average of T″ bits to account for reject time, this tells us how large the bit array N″ needs to be to keep the false positive probability below P″. In other words, we can see that N″ is proportional to the number of input values (n).
So if you want a low false positive probability P″ and fast T″, N″ needs to be larger.
In the paper, the Bloom filter was approached as a use case for reducing unnecessary disk accesses.
When processing 500,000 words, the assumption was that 90% could be handled simply with rule-based processing, but 10% needed to reference an actual dictionary. In this case, the 10% needs to be looked up from a dictionary on disk, but querying the disk for every single word is slow. So the scenario was: put only this 10% in a Bloom Filter, skip if it says "does not exist," and check the disk only when there's a possibility it exists.
In this scenario, when the error probability P was reduced significantly (which increased the Hash area accordingly), the actual disk access rate dropped dramatically. Specifically, the paper showed that a Bloom Filter with an error probability of about 1.5% achieved approximately 88% accuracy.
Since this is a paper from 1970, I think this method was introduced because disk access was a significant burden back then. But it was the starting point that led to probabilistic data structures being used to this day, so I looked into it further. So the takeaway from the Bloom filter data structure is that by allowing a small margin of error (false positives), fast testing is possible even with small amounts of space. This can bring significant benefits in systems processing large-scale data.
A Question About the Bit Size N″
When I first encountered the Bloom Filter concept, the part I couldn't understand the most was: why isn't the bit value INT.MAX or LONG.MAX? Since the return value of hash functions is typically int in my programming experience, shouldn't the bit array size always be INT.MAX? — that was my very modern-programmer way of thinking. But after reading this paper (asked GPT to explain it in Korean..), I realized that back then it was an era of manual memory allocation, so that's how it was. And in practice, this N value can be adjusted regardless of the hash function's return type being Int.
int hashValue = hashFunction(x);
int columnIndex = hashValue % N;
This is because we can use modular arithmetic with whatever N value we want in order to control actual memory usage.
In practice, without using this probabilistic data structure, storing n elements would take O(n) space complexity. But with this probabilistic data structure, you only need O(d) space — the number of hash functions — to determine false positives for n elements, so I came to understand that this provides a huge spatial advantage in large-scale systems.
Redis Probabilistic Data Strucutures
If you actually want to use it, do you have to write the bloom filter logic yourself? Absolutely not — it's a paper from 1970, there's got to be at least one library for it. Most notably, Redis already explains and provides probabilistic data structures.
When actually using a Bloom Filter with Redis, it uses an approach where you define it based on the error_rate. Unlike the examples I used above where we pre-define the d value (number of hash functions), note that Redis takes a different approach. It seems they decided that lowering the error rate matters more than having developers manually adjust the d value.
You can't use the Bloom Filter data structure with just a regular Redis server. You need an additional module, and since that's a hassle, I used a pre-built Docker image.
docker run -d --name redis-stack -p 6379:6379 redis/redis-stack-server:latest
You can easily use bloom filters through redis-cli. Using the RESERVE command, you can set the error probability and expected number of elements, and the bloom filter gets configured accordingly — you can also check its information with the BF.INFO command. As you can see from the EXISTS results, it confirms the false positive behavior (it returned true for value "a" which was never actually added). This happened because I intentionally set a high error rate and low expected element count.
So when using bloom filters with Redis, you can intentionally set a low error rate — if accuracy is important, make sure to properly configure the error_rate and capacity (expected number of elements). When checking with INFO, you can clearly see that the size is allocated larger to reduce the error rate.
Using BF.DEBUG, you can get more detailed information at the byte level.
Since it's a paper from 1970, quite a lot of extended versions have come out. On the Redis site referenced above, you can see that besides the most primitive Bloom Filter, they also offer Scalable Bloom Filter and Cuckoo Filter. While looking around, I was happy to find a paper published by alumni from my university (Ternary Bloom Filter), and as described in the paper, I could see that these are often considered as algorithms used in network transmission.
Structure
Feature Extension
Key Characteristics
Counting Bloom Filter
Supports deletion
Replaces each bit with a counter (1 bit → k bits).
Scalable Bloom Filter
Auto-scaling size
Adds a new Bloom Filter when false positive limit is exceeded
Compressed Bloom Filter
Compressed storage
Optimized for network transmission/storage
Cuckoo Filter
Deletion + improved accuracy
Based on Cuckoo Hashing. Stores fingerprints of actual keys
Ribbon Filter(Facebook)
Compression + fast queries
XOR-based lightweight structure, very small false positive rate
Xor Filter(Google)
Fixed key set
Based on perfect hashing, very fast and compact
The Counting Bloom Filter (2010 paper) replaces bits with counters instead of just setting them to 1, so it actually needs to be stored as a 2D array. On add, it increments (+1) the value at the corresponding bit position, and for deletion, it decrements (-1). At first glance, this seems similar to Count-Min Sketch, but since the use cases and query intentions differ, the internal data structures (actual N and d) can be different, so they should be distinguished.
The Scalable Bloom Filter (2007 paper) works by adding new Bloom Filters and layers to accommodate more items. These additional layers keep the same number of hash functions (d) but use a wider bit array (N). Since the same hash functions are used, it first checks across all layers to confirm non-existence before adding to the current filter. However, having more layers means using more storage, which significantly degrades performance. So even though it's "Scalable," knowing the exact number of items to include (n) is still important.
Also, the Redis Bloom Filter mentioned above provides the option to use Scalable Bloom Filter. In fact, when I added more elements to the error_rate 0.5, capacity 10 example used above and ran INFO, the Number of filters went from 1 to 2, and the size increased from 104 to 184.
Left: Before adding elements beyond capacity. / Right: After adding elements beyond capacity
The Compressed Bloom Filter (2002 paper) works the same as a regular Bloom Filter — hashing and setting bits — but with an added compression step for the bit array.
Cuckoo Filter
While a Bloom Filter is characterized by being a bit array that sets bits to 1 at positions determined by hash functions, the Cuckoo Filter solves the problem using a bucket array. It was born out of the issues that Bloom Filters don't support deletion, and that Counting Bloom Filters do support deletion but use more memory which can cause performance degradation. The Cuckoo Filter improved on these points and actually achieved better performance as well.
It fundamentally operates based on Cuckoo Hashing—instead of setting each bit array index to 1 like in a Bloom Filter, it inserts the item's fingerprint into a bucket. When a collision occurs, it evicts and relocates.
If one of the two buckets has an empty slot, insert there
If both are full,evictan existing item and relocate it
This process repeats until an empty space is found or the maximum retry count is reached
The fingerprint means storing only a portion of the input's hash value rather than the entire input. Thanks to this, memory usage is reduced and deletion becomes possible. (We'll look into this more below.)
To understand the insert mechanism and the basic data structure, try using the visualization tool below—it helps a lot.
Let me walk through the insert scenarios based on what's in the paper. For now, think of it as inserting the item itself.
a) We're trying to insert item x, but buckets 2 and 6—the results of h1(x) and h2(x)—are already full. In this situation, we decide to evict item a from bucket 6. Since a has been evicted, it needs to be relocated, so we look up h1(a) and h2(a) and relocate it to bucket 4 (the other candidate bucket). However, this means c, which was in bucket 4, now needs to be evicted. Likewise, c looks up h1(c) and h2(c) and relocates to bucket 1.
b) After the relocation process is done, x is successfully placed in bucket 6, and as a result of all the relocations, a ends up in bucket 4, b in bucket 2, and c in bucket 1.
c) In a cuckoo filter, each bucket can hold b entries. Since cuckoo filters find empty space through eviction when hash collisions occur, if each bucket only had 1 entry, the eviction + relocation process would happen excessively like in scenarios a and b, causing performance degradation. By allowing multiple entries per bucket, the goal is to increase insertion success rates and reduce evictions. So even items with the same bucket index can coexist by having multiple entries within a bucket, leading to more stable performance.
Also, if you play around with the visualization tool above, you'll notice that when there are few entries, the eviction → relocation cycle can end up in an infinite loop. It's like the scenario in a and b where there's simply no space left to insert. To handle this, the cuckoo filter has a maximum retry count, and when this limit is exceeded, it breaks out of the infinite loop and signals that insertion has failed—prompting actions like increasing the number of entries per bucket or expanding the bucket size.
Fingerprint and Partial-Key Cuckoo Hashing
As briefly mentioned above, the cuckoo filter doesn't store the full data in the hash table. Instead, it stores only a fingerprint (a hash summary) to improve space efficiency. So during insertion, the bucket candidates are determined solely by the fingerprint value. The problem is, when an eviction happens, we only have the fingerprint—so we can't compute the alternate location from the original key anymore.
That's where the partial-key cuckoo hashing technique comes in.
By XORing the hash of the fingerprint with the current position, we can determine the index of the alternate bucket.
So originally we assumed there were separate h1 and h2 hash functions, but to solve the problem of inserting with only fingerprints, h2 is now derived from h1. Nevertheless, since XOR is used, it prevents buckets from being adjacent to each other, which seems to be why they considered it a good hash for reducing collisions. (If you use an 8-bit fingerprint, relocation is possible up to 256 (= 2^8) positions away.)
That said, partial-key cuckoo hashing does have its drawbacks:
Reduced number of hash combinations Standard cuckoo hashing generates h1 and h2 with different functions, but partial-key hashing derives from the existing h1. This inevitably reduces the number of h1/h2 combinations and can increase the probability of collisions.
Inserting different items with the same fingerprint Different items x and y can share the same fingerprint. So it's possible for the same fingerprint to appear multiple times within a bucket. However, if the same item is inserted 2b or more times (b = slots per bucket), both buckets can fill up completely, causing overflow.
These are the algorithms taken from the paper.
Lookup is really straightforward. You compute the two buckets and if the fingerprint exists in either one, it's considered to exist. So there are no false negatives here (reporting something doesn't exist when it actually does). However, false positives can occur—similar to Bloom Filters—when a different item happens to hash to the same bucket.
Deletion is also simple. If the fingerprint exists in either of the two buckets, just remove it from that bucket. However, just like with lookups, since we're only comparing fingerprints, it's worth noting that it could be a different item with the same fingerprint as x. (If x and y have the same fingerprint, even after deleting x, if y is still present, it may still report that x exists.)
Results on Actual Efficiency
When using a cuckoo filter like this, there are many interdependent values to consider. Let me pull a few experimental results from the paper.
1. Analysis of Fingerprint Length
- load factor =a value used to determine when the table needs to expand based on how full it is relative to its capacity - bucket size = the entry size mentioned above, i.e., the number of entries allowed per bucket - m = the number of buckets (table size)
As the number of fingerprint bits increases, there are more bits available to identify each item, so false positives naturally decrease. However, as the graph shows, whether the number of entries is 4 or 8, the load factor stays around 95% and 98%—so it doesn't have a major impact overall. A larger entry size does increase the load factor, but it also means more slots to check during lookup. Additionally, as the number of buckets grows, longer fingerprints are needed—slightly longer fingerprints are required to prevent collisions.
So this shows that even with just 6–8 bit fingerprints, a high fill rate can be achieved. By finding the right fingerprint length, they demonstrated efficient operation.
2. Space Optimization Experiment
The 3% crossover point is important—if you require a false positive rate lower than 3%, the cuckoo filter is more space-efficient; otherwise, the Bloom Filter wins in space efficiency. The purple lower bound means that no probabilistic data structure can go below this limit.
In other words, at the 3% false positive threshold, storing one item takes 7.2 bits. If you want a false positive rate lower than that, Bloom Filters need more bits, so the cuckoo filter uses fewer bits—making it more space-efficient.
There's a lot more content in the paper, but... I'll skip the rest.
One more thing worth noting is that Redis also provides both Bloom Filter and Cuckoo Filter separately, thanks to their different space efficiency and deletion capabilities. Redis automatically allocates space based on error rate calculations, so if you actually want to use a cuckoo filter, checking out the Redis IO code is a good idea.
It claims to be a smaller and faster filter than both Bloom Filter and Xor Filter. The Xor Filter itself is different from the cuckoo filter—it doesn't support deletion, but it has better space efficiency compared to Bloom Filters. So what the Ribbon Filter is really claiming is that among filters that don't support deletion, it has the best space efficiency. However, it's important to note that since deletion is not supported, it's only suitable for large-scale read-only environments.
According to the engineering blog above, the advantages include O(1) query time and 1/3 memory savings compared to Bloom Filters. Additionally, four key performance metrics are hidden behind a simple API and can be tuned as needed: 1. number of keys 2. memory usage 3. CPU efficiency, 4. accuracy
It uses something called a Ribbon Matrix, and because it physically looks like a ribbon, that's how the Ribbon Filter got its name.
Wrapping Up
I plan to study the Ribbon Filter in more depth when I get the chance. I've been feeding the paper into GPT, trying to understand it, asking more questions, and studying that way—and honestly, my brain started melting a bit. Anyway, from a software engineer's perspective, I got interested because probabilistic data structures can reduce DB access through fast false-positive checks while using minimal space, which makes them really useful for large-scale systems. Actually, what I originally came across in my system design study group was Count-min Sketch—I plan to write up what I've learned about that separately. That's it!
MCP 편하다고 막 써도 괜찮을까? | Is It Really Okay to Use MCP Just Because It's Convenient?
쟈 미
728x90
LLM 정말 핫하긴하다. 근데 그래서 개발자 못하려나 걱정이 있다. 최근엔 chatgpt, cluad, perprexity 필요에 적극적으로 업무에도 활용하고 공부에도 정말 도움을 많이 받고있다. Junie, Copliot도 코드 짤때 정말 적극 활용하고 있는 요즘이다.
실제로 linux script 실행할때나 간단한 script 코드들 짤 때. 생산성이 정말 많이 올라갔다. 예를들면 log format이 이 형태인데 grep으로 이 포맷에서 이 필드를 가진 로그가 총 몇개인지, unique 값은 몇개인지 전체 log row 중에서의 비율은 몇개인지 간단한 한줄짜리 linux command 알려달라고 할 때 일회성으로 생각없이 쓰게되는 것 같다. 전반적인 구조를 고려해서 짜야하는 코드는 아직 잘 모르겠다. 구조를 고려한건 아무래도 Junie가 잘 해주는것 같긴한데 그래도 결국 실무 코드에서는 실무자가 배포 부담을 져야하니 쉽지않다.
여튼 이런식으로 그동안은 써보기만하다가 이제는 슬슬 이것들의 동작원리나 조심해서 써야하는 부분들을 찾아봐야하려나 하는 고민이 생겼다. mcp의 등장이후로 token 연동해서 외부 api를 (mcp server) llm으로 활용하는 경우도 점점늘어나고 있어서 그렇다. 특이나 아래글들을 읽고 좀 알아봐야겠다는 생각이 들었는데
{
name: "get_issue",
description: "Get details of a specific issue in a GitHub repository.",
inputSchema: zodToJsonSchema(issues.GetIssueSchema)
},
실제로 안의 inputSchema의 내용을 따라가면 github api 호출을 하고있음을 알 수 있다. 결국 mcp는 llm이 사용하기 위한 @Controller를 하나 뚫어둔거라고 생각하면 된다. 어떻게? description과 name을 적당히자연어로 잘 적어서
그래서 이제 llm + mcp를 사용하게되면 서버 프로그래밍 상으로 여러 api요청을 연쇄적으로 그때그때 인자값을 열심히 연결해서 코딩해서 넣던걸 자연어로 원하는 응답을 받을 수 있다는 장점이 생기게 된다.
요구사항이 아래와 같다고하자.
내가 가진 GitHub repository 중에 star가 가장 많은 걸 알려줘.
그리고 그 repository의 최근 커밋 수랑 contributor 수, issue 개수도 알려줘.
예전에 코딩으로 이 요구사항을 해결해야했으면 아래와 같은 수도코드를 작성하기 위해 api 명세를 확인하고.. 틀린지 아닌지 확인하고 올바른 dto 매핑인지 살펴보고 등등 귀찮았다. 사실 아래의 수도코드로는 위에 있는 요구사항을 전부 해결할 수 없다. (더 해야한다)
# 기존 방식
import requests
headers = {
"Authorization": "Bearer <MY_TOKEN>",
"Accept": "application/vnd.github+json"
}
# 1. 내 전체 repo 가져오기
repos = requests.get("https://api.github.com/user/repos", headers=headers).json()
# 2. 가장 star 많은 repo 찾기
top_repo = max(repos, key=lambda r: r["stargazers_count"])
# 3. 커밋 정보 가져오기
commits = requests.get(f"https://api.github.com/repos/{top_repo['full_name']}/commits", headers=headers).json()
# 4. 통계 출력
print(f"{top_repo['name']}의 커밋 수: {len(commits)}")
근데 이제 llm과 함께 mcp를 사용하게 되면 그냥 저 요구사항을 입력하면 된다.
이 요구사항을 만족하기위해 필요한 mcp server description을 알아서 판별하고 알아서 인자값을 넣어서 github api 를 호출한다. 실제로 저기 블록에 있는 search_repositories 가 호출한 mcp server 프로토콜 명을 뜻한다.
결국 자연어에서 어떤 api를 써야하는지 찾기위한 힌트를 적기만해도 api endpoint가 뚫리는게 MCP이다
근데 이 작은 요구사항을 해결하려고 llm은 api 콜을 9개나 썼는데, 정말 이렇게까지 많이 필요한건가? 엄청 많이 하는거아닌가? 사실 개발자가 직접 코딩을 했다면 이렇게까지 많은 api를 썼을까? 이런 생각이 든다. (근데 편하긴하다)
예전 방식은내가 어떤 API를 호출하고 있는지, 어떤 데이터를 어디로 보내고 있는지를 내가 다 컨트롤할 수 있었다.
MCP 방식은내 의도를 파악한 LLM과 MCP 서버가 대신 처리해주는 구조이기 때문에,내가 뭘 보내고 있는지 명확히 보이지 않을 수도 있다.
지금까지 설명한 이 흐름이 mcp 문서에서 설명한 architecture의 MCP Server C <-> Remote Service C 부분이다. 이걸 이해했다면 local data source에 대한것도 금방이해하리라 본다.
2. LLM + MCP가 만들어내는 보이지않는 API Call 폭발
위와같이 실제로 MCP를 통해 LLM이 API를 호출하는 과정을 추적해보면, 단일 프롬프트가 여러 개의 API 호출로 이어지는 경우를 확인할 수 있었다. 이러한 호출은 로그나 네트워크 트래픽을 분석하여 파악할 수 있으며, 예상보다 많은 호출이 발생함을 알 수 있었다.
그렇다면 기존에 서비스들이 본인들이 제공하던 open api에 더불어 mcp server 제공하게되면? 본인 서비스의 호출이 증가하게 되고 llm + mcp가 만들어내는 트래픽까지 감당해야하게 되면서 결국 서버 프로그래머들의 대규모 트래픽 관리 능력이 더더욱 중요해지는게 아닐까? (희망회로..)
한편으로는 api 호출수로 과금을 하는. 서비스라면 mcp server 호출을 유도해서 돈을 아주 잘 벌 수 있게 되겠지 싶기도 하다.
1. 캐싱전략
a. mcp server inmemory caching
LLM이 동일한 질문을 여러 번 할 수 있고, API 응답은 보통 몇 초 단위로 바뀌지 않기 때문에 응답 결과를 캐싱해두면 서버 부하를 많이 줄일 수 있을 것으로 예상한다. 이때 mcp server는 본인의 local에 있다는 점을 잘 활용하면 remote service까지 가지 않게 트래픽을 조절할 수 있다. remote service 입장에서는 사실 기존의 클라이언트에서 local storage에 정보를 가지고 서버에 api를 호출하지 않는것과 같은 맥락
import express from "express"
import NodeCache from "node-cache" //가볍고 직관적인 in-memory 캐시 라이브러리야. TTL 기반으로 자동 만료
import axios from "axios"
const app = express()
const cache = new NodeCache({ stdTTL: 300 }) // 기본 TTL 5분
app.get("/commits/:owner/:repo", async (req, res) => {
const { owner, repo } = req.params
const cacheKey = `commits:${owner}/${repo}`
// 1. 캐시에 있으면 리턴
const cached = cache.get(cacheKey)
if (cached) {
console.log(`[CACHE HIT] ${cacheKey}`)
return res.json(cached)
}
// 2. 외부 API 호출
const response = await axios.get(
`https://api.github.com/repos/${owner}/${repo}/commits`,
{
headers: {
Authorization: `Bearer ${process.env.GITHUB_TOKEN}`,
Accept: "application/vnd.github+json"
}
}
)
const data = response.data
// 3. 캐시에 저장
cache.set(cacheKey, data)
console.log(`[CACHE MISS] ${cacheKey} - 저장 완료`)
res.json(data)
})
위와 같은 코드로 api를 호출할때 caching 해두는 것 처럼 내가 만든 mcp서버가 외부 api 를 호출하는 서버라면 이 전략을 사용해서 외부 api 호출량을 줄이는 방법이 있을 것으로 보인다.
다만 이렇게 했을때 client에서 "내용이 부정확하다", "잘못된 내용으로 보인다", 등의 프롬프트가 있다면 cache reset 하고 직접 api에 호출한다던지 전략이 필요해보인다.
b. prompt caching / semantic caching
LLM에게 동일한 프롬프트를 반복해서 보냈을 때, 매번 새롭게 생각(=토큰 소모)하지 않도록, 이전 응답을 미리 캐시해두는 방식
“We do not currently cache prompts on our side. However, we recommend client-side caching if you’d like to avoid resending the same prompt multiple times.”
mcp client라고 볼수 있는 claud가 제공하고 있는 방식이다. claude나 OpenAI 같은 LLM Provider는 사실상 MCP의 client 역할을 하고 있고, 결국 client 입장에서는 llm 사용요금과도 연결되는 (돈을 아끼면서 llm을 쓰고싶은..) 부분이라서 공식적으로 지원하고 있는것으로 보인다.
요약하면 claud 사용시 아래와 내용을 추가하면 prompt cache가 활성화 된다는 이야기이다.
"cache_control": {"type": "ephemeral"}
실제로 model 로 부터 응답을 받는데 더 작은 시간이 소요된다는 예시는 아래에 있다. Example1의 non-cached api call과 cached api call을 비교하면 20s > 2s 로 많이 줄어들었음을 확인할 수 있다.
Example2에서 응답 시간은 초기 캐시 설정 후 거의 24초에서 단 7-11초로 단축되었고, 응답 전반에 걸쳐 동일한 수준의 품질을 유지한다고한다. 7~11초의 이유는 대부분은 응답을 생성하는 데 걸리는 시간 때문이며, 캐시 breakpoints를 계속 조정하면서 입력 토큰의 거의 100%가 이후에 캐시되었기 때문에, 사용자 메시지를 거의 즉시 읽을 수 있었다고한다.
1번째 ... N 번째 시도
prompt_caching을 사용하면 mcp server가 효율적이게 될까? 라고하면 그건 또 상황에 따라 다르다.
1. MCP 서버가 단순 API bridge역할만 하고있다면
외부 api 응답 자체를 mcp 서버 내부에서 캐싱하고있는 것이 훨씬 효율적이다. 왜냐면 prompt를 안쓰니까. 즉, MCP 서버가 단순 API bridge역할만 하고있다면 1번과 같이 api요청에 대한 inmemory caching이 더 효과적이다.
2. mcp 서버가 여러가지 역할을 하고있다면?
지금까지 알아본 prompt caching이 효율적이려면 mcp server가 LLM prompt 결과생성까지 담당하는 구조일 때만 효율적이다.
사용자 → LLM 프롬프트 구성 → 외부 API 호출 → 응답 생성 → LLM에 전달
mcp 서버가 중간 로직과 응답 조합까지 처리하는 경우라면, 같은 프롬프트에 대해 응답을 만들 수 있기때문에 mcp 자체에서 캐싱할 수 있다.
이때 같은 프롬프트에 대한 캐싱만 아니라 의미상 비슷한 내용을 캐싱하기 위해 semantic caching을 이용하는 방법도 있는걸로 안다. 의미적 유사도를 계산하여 vector화 시키고 이것을 임베딩한다. 새로운 입력이들어왔을때 이 입력을 마찬가지로 vector화시키고 임베딩된 데이터와 유사하다면 그 응답을 반환하는 방법이라고 알고있다. 근데 직접 한다고 생각하면 머리아프다 그만알고싶다
여튼 말하고자 하는 바는 기존의 remote server api 제공자(지금의 서버개발자들)가 mcp server까지 제공하게된다면 어떤 캐싱 전략을 취하는지도 중요한 시대가 되어버렸다. 기존의 remote server 단 캐싱을 믿고 몰려드는 트래픽을 멋진 서버구조로 해결하겠어! 라는 마음가짐이 아니라 제공하는 mcp server 단에도 inmemory caching을 달아서 remote server에 몰리는 트래픽을 줄이는 방법을 고려해야한다.
근데 생각해보면 remote server 단 api 호출 수로 유저가 과금하게 만드는 구조라면 일부러 mcp server에 캐싱을 안 달 것 같기도하다. 유저입장에선 api call bridge 역할의 mcp server들의 호출들을 전부 caching해주는 caching mcp server를 사용하는게 나을 수도
2. 요청 제한 설정
위에 말했듯이. MCP를 쓰기 시작하면서, LLM이 단순히 한 줄 프롬프트만 받아들이는 게 아니라, 그 프롬프트를 해석해서 여러 개의 외부 API를 한꺼번에 호출하기 시작한다는 점이었다.
예전에는 사용자가 직접 API를 호출했기 때문에 “한 번에 몇 개 요청 보낼지”, “실행 시간이 얼마일지”를 어느 정도 예측할 수 있었다. 하지만 LLM은 한 문장의 목적을 이루기 위해 5개, 10개 넘는 요청을 연쇄적으로 호출할 수도 있다.
a. rate limiting
문제는 기존 전통적인 remote server api들은 rate limiting 제한이 있다. 1초에 3개이상의 요청을 보내지 말라는 등의 요구사항으로. 고로 mcp server에서 api 콜을 보낼 때 rate limiting을 고려해야한다. ( 기존 전통적인 client들에서 고민하던 것들을 mcp server에 녹이는 느낌이 든다)
실제로 위 mcp서버는 Qlik Cloud API를 사용해서 시각화하는 목적을 갖고있는데, 실제 호출부의 코드를 보면 rate limiting 적용을 위해 delay를 적용해둔 걸 확인할 수 있었다.
const data = await withRetry(async () => chartObject.getHyperCubeData('/qHyperCubeDef', [{
qTop: startRow,
qLeft: 0,
qWidth: metadata.totalColumns,
qHeight: rowCount
}]));
if (data?.[0]?.qMatrix) {
allData.push(...data[0].qMatrix);
}
// Add delay between chunks to avoid rate limiting
if (startRow + pageSize < rowsToFetch) {
await delay(REQUEST_DELAY_MS);
}
페이지네이션 하는 forloop 안에 rate limiting 코드가 들어있었음.
외에도 고려하면 좋을 것들로
b. timeout
mcp server에서 외부 api를 계속 호출하는데 응답이 너무 느리게 오는 상황이라면 일부러 강제종료를 시켜서 다른 mcp tools를 이용하여 llm 이 결과를 낼수록 유도하기 때문에 timeout 설정도 잘해주는게 좋다.
c. 병렬처리 제한.
llm이 mcp tools를 이용하여 병렬로 여러 요청을 날리면 그만큼 remote server에 영향이 커지게 된다. a에서의 ratelimiting을 건다고해도 한개의 api요청에 대해서만 ratelimiting이 걸리게하는 방식으로 코드를 작성한걸 볼 수 있다. 그러나 mcp는 동시에 여러개의 tools를 사용하여 api 요청을 하게할 수 있으니 tools를 동시에 여러개 실행하게 되면 remote server에 부하가 동시에 몰릴 수도 있게되는 상황이다.
고로 java 기준은 api호출시 ExecutorService를 이용해서 고정된 쓰레드 풀로 병렬작업을 실행하도록 병렬처리 작업개수를 조절한다거나 하는 방법을 이용하는 것이다.
d. circuit breaker
나의 remote server가 죽었는데도 llm으로 인해 계속 mcp가 retry를 하게된다면? remote server에 오히려 요청이 몰리면서 c에 해둔 병렬처리 제한이 같이 걸려있다면 오히려 리소스를 사용하지 못하는 상황이 될 수 있다. 이런 상황을 막기위해 일정 횟수 이상 실패시 api 호출을 차단하는 로직들이 필요할 수 있다.
결국 써놓고 보니 mcp server를 구현하는 것은 server와 client를 동시에 제공하는것과 같은느낌이 들지 않는가? mcp server를 기존시스템에 녹여서 사용하기 위해서는 기존에 client단에서 성능을 올리기 위한 여러 트릭들을 mcp server에 적용하면 되는 느낌이다.
3. 보안
제일 무섭다.
4. 기술은 진화하지만, 본질은 크게 다르지 않다
llm이 나오고 나서 “이제 개발자는 할 일 없어지는 거 아닌가?“라는 얘기를 자주 듣는다. 우선 mcp 자체만 놓고봤을 땐, 새로운 형태의 api 프로토콜일 뿐이다. api 요청이 더 자연어에 가까워졌을 뿐
그래서 프론트에서 들어오는 요청이 자연어가 되었다고해서 그걸 처리하는 서버의 역할까지 사라지는건 아니다. 오히려 유저 요청을 더. 편하게 쓸 수 있게되었다는 점이고.
결국 서비스를 만들기 위해서는 여전히 특정 플로우를 설계해야 하고, 보안과 성능을 고려해서 캐싱도 걸고, 트래픽도 분산해야 한다. 이건 예전에도 개발자가 하던 일이었다.
이전에 pc만 쓰던시대에서 mobile도 쓰는 시대로 넘어갈때, 원래도 서버라는 개념이 있었다. 다만 mobile로 넘어가면서 그 서버들이 여러 환경에서 요청을 받을수있고 접근이 쉬워졌고 그러면서 서버에서 처리해야할 요청량들이 엄청나게 많아졌다. 따라서 서버에서 이런 요청을 처리하기 위해 많은 기존의 서버개발자들이 머리를 싸매 성능향상을 위해 여러 방법론을 제안하고 기존의 개념들을 활용한 아키텍쳐가 발생하게 된것이 아닌가?
이제 mobile app을 쓰던 시대에서 llm으로 서비스를 제공받는 시대로 넘어감에 따라서. 이전과 거의 비슷하다. 이전과 같이 유저의 서버 요청이 더 쉬워짐에 따라서 서버는성능향상에 더 몰두하게 될 것이고, 기존의 여러 client, server 통신, 보안등에 대해서 기존의 개념들을 활용한 아키텍처가 생기고 또 서버 성능을 끌어올리기위한 노력들이 더더욱 생길 것 같다.
그래서 개발자가 사라지는게 아니라 오히려 이런 부분을 채워줄 수 있는 개발자로 나아가야할 것 같다. 결국 기존 기술들의 개념을 잘 이해하고 있는 개발자들이 LLM 시대에도 더 필요한 역할을 맡게 되지 않을까? 그래서 결국 개발공부는 해야할것 같다는 결론이 나버렸다..
끗
근데 난 gpt 로 블로그 글은 못쓰겠다. 얘가 써주는 내용은 너무 오글거림
LLMs are really blowing up. But honestly, I'm a bit worried about whether developers will become obsolete. Lately, I've been actively using ChatGPT, Claude, and Perplexity for work and studying — they've been incredibly helpful. These days, I'm also heavily using Junie and Copilot when writing code.
My productivity has genuinely skyrocketed, especially when running Linux scripts or writing quick script code. For example, when I have a log format like this and I need a one-liner Linux command to grep for how many logs have a certain field in that format, how many unique values there are, and what percentage of total log rows they represent — I just mindlessly ask for it and use it as a throwaway thing. For code that requires thinking about the overall architecture, I'm still not so sure. Junie seems to handle structural considerations pretty well, but at the end of the day, in production code, the developer has to bear the deployment risk, so it's not that simple.
Anyway, up until now I've just been casually using these tools, but I'm starting to think it's time to look into how they actually work and what to watch out for. Especially since the arrival of MCP has led to more and more cases where people connect tokens to use external APIs (MCP servers) through LLMs. In particular, reading the articles below made me think I should dig into this a bit more.
I think it's time to learn at least the basics now. This is written after looking into MCP, so it might not be entirely accurate. If there's anything that needs correcting or more research, let me know in the comments.
The way I see it, until now we've been providing services through communication protocols like HTTP APIs, TCP, etc., defining request and response formats. But now, the world is shifting toward providing services not through communication protocols, but through designated LLM keywords.
Say your goal is to fetch issues from a specific repo on GitHub. Previously, you'd have to manually match the HTTP API specifications that GitHub provides, carefully crafting the request format exactly how they want it, like this:
With MCP, you just type a prompt like the one below, and the MCP server maps it to the API above and returns the response nicely for you.
gem-api repository의 첫번째 issue가 뭔지 알려줘.
If you actually look at the GitHub MCP server implementation, it's structured similarly to how we expose endpoints using @Controller — the MCP server adds descriptions that it can reference for mapping, essentially opening up MCP server endpoints.
{
name: "get_issue",
description: "Get details of a specific issue in a GitHub repository.",
inputSchema: zodToJsonSchema(issues.GetIssueSchema)
},
If you follow the inputSchema inside, you can see that it's actually making GitHub API calls under the hood. In the end, you can think of MCP as opening up a @Controller for the LLM to use. How? By writing the description and name appropriately in natural language.
So when you use LLM + MCP, you gain the advantage of receiving the responses you want in natural language, instead of having to chain multiple API requests together in server code, painstakingly passing arguments from one call to the next.
Let's say the requirement is something like this:
내가 가진 GitHub repository 중에 star가 가장 많은 걸 알려줘.
그리고 그 repository의 최근 커밋 수랑 contributor 수, issue 개수도 알려줘.
If you had to solve this requirement with code back in the day, you'd have to check API specs, verify whether your code is correct, make sure the DTO mapping is right, and so on — all just to write pseudocode like the one below. It was a hassle. And honestly, the pseudocode below doesn't even fully satisfy the requirements above. (You'd need to do more.)
# 기존 방식
import requests
headers = {
"Authorization": "Bearer <MY_TOKEN>",
"Accept": "application/vnd.github+json"
}
# 1. 내 전체 repo 가져오기
repos = requests.get("https://api.github.com/user/repos", headers=headers).json()
# 2. 가장 star 많은 repo 찾기
top_repo = max(repos, key=lambda r: r["stargazers_count"])
# 3. 커밋 정보 가져오기
commits = requests.get(f"https://api.github.com/repos/{top_repo['full_name']}/commits", headers=headers).json()
# 4. 통계 출력
print(f"{top_repo['name']}의 커밋 수: {len(commits)}")
But now with LLM + MCP, you just type in the requirement as-is.
It automatically figures out which MCP server descriptions are needed to fulfill the requirement, fills in the arguments on its own, and calls the GitHub API. In fact, the search_repositories shown in that block represents the name of the MCP server protocol that was called.
Ultimately, MCP is about opening up an API endpoint just by writing hints in natural language so the LLM can figure out which API to use.
But to handle this small requirement, the LLM made 9 API calls — do we really need that many? Isn't that way too much? Honestly, would a developer have used this many API calls if they coded it themselves? That's what I'm thinking. (But it is convenient, though.)
With the old approach,I had full control over which APIs I was calling, what data I was sending, and where it was going.
With the MCP approach,the LLM and MCP server handle things on your behalf based on their interpretation of your intent, which meansyou might not always have clear visibility into what's being sent.
The flow I've described so far corresponds to the MCP Server C <-> Remote Service C part of the architecture explained in the MCP documentation. Once you understand this, you should be able to quickly grasp the local data source part as well.
2. The Hidden API Call Explosion Created by LLM + MCP
As shown above, when you actually trace the process of an LLM making API calls through MCP, you can see that a single prompt leads to multiple API calls. These calls can be identified by analyzing logs or network traffic, and it turns out there are far more calls happening than expected.
So what happens when existing services start offering MCP servers on top of the open APIs they already provide? Their service call volume will increase, and they'll have to handle the additional traffic generated by LLM + MCP — which means server programmers' ability to manage large-scale traffic becomes even more important, doesn't it? (Hopeful thinking...)
On the other hand, for services that charge based on API call volume, incentivizing MCP server usage could be a great way to rake in money.
1. Caching Strategies
a. MCP Server In-Memory Caching
An LLM can ask the same question multiple times, and API responses typically don't change within a few seconds, so caching response results should significantly reduce server load. If you take advantage of the fact that the MCP server lives on your local machine, you can control traffic so it never even reaches the remote service. From the remote service's perspective, it's essentially the same concept as a traditional client holding information in local storage and not making API calls to the server.
import express from "express"
import NodeCache from "node-cache" //가볍고 직관적인 in-memory 캐시 라이브러리야. TTL 기반으로 자동 만료
import axios from "axios"
const app = express()
const cache = new NodeCache({ stdTTL: 300 }) // 기본 TTL 5분
app.get("/commits/:owner/:repo", async (req, res) => {
const { owner, repo } = req.params
const cacheKey = `commits:${owner}/${repo}`
// 1. 캐시에 있으면 리턴
const cached = cache.get(cacheKey)
if (cached) {
console.log(`[CACHE HIT] ${cacheKey}`)
return res.json(cached)
}
// 2. 외부 API 호출
const response = await axios.get(
`https://api.github.com/repos/${owner}/${repo}/commits`,
{
headers: {
Authorization: `Bearer ${process.env.GITHUB_TOKEN}`,
Accept: "application/vnd.github+json"
}
}
)
const data = response.data
// 3. 캐시에 저장
cache.set(cacheKey, data)
console.log(`[CACHE MISS] ${cacheKey} - 저장 완료`)
res.json(data)
})
Like the code above that caches API call results, if the MCP server you built is one that calls external APIs, you could use this strategy to reduce the number of external API calls.
However, if the client sends prompts like "the information seems inaccurate" or "this looks wrong," you'd need a strategy like resetting the cache and calling the API directly.
b. Prompt Caching / Semantic Caching
When the same prompt is repeatedly sent to an LLM, this approach pre-caches previous responses so it doesn't have to think from scratch (= consume tokens) every time.
“We do not currently cache prompts on our side. However, we recommend client-side caching if you’d like to avoid resending the same prompt multiple times.”
This is an approach provided by Claude, which can be considered an MCP client. LLM providers like Claude or OpenAI essentially play the role of MCP clients, and since from the client's perspective this directly ties into LLM usage costs (wanting to use LLMs while saving money..), they seem to officially support it.
In short, when using Claude, adding the following activates prompt caching.
"cache_control": {"type": "ephemeral"}
An example showing that it actually takes less time to get a response from the model is below. Comparing the non-cached API call and cached API call in Example 1, the time dropped significantly from 20s to 2s.
In Example 2, the response time dropped from nearly 24 seconds to just 7-11 seconds after the initial cache setup, while maintaining the same level of quality across responses. The 7-11 seconds is mostly due to the time needed to generate the response, and by continuously adjusting the cache breakpoints, nearly 100% of input tokens were cached afterwards, which means the user message could be read almost instantly.
1st attempt ... Nth attempt
Does using prompt_caching make MCP servers more efficient? Well, that depends on the situation.
1. If the MCP server is only acting as a simple API bridge
It's much more efficient to cache external API responses internally within the MCP server. Because you're not using prompts at all. In other words, if the MCP server is only acting as a simple API bridge, in-memory caching for API requests as described in option 1 is more effective.
2. What if the MCP server handles multiple responsibilities?
The prompt caching we've looked at so far is only efficient when the MCP server is structured to handle LLM prompt result generation as well.
User → LLM prompt composition → External API call → Response generation → Pass to LLM
If the MCP server handles intermediate logic and response composition, it can generate responses for the same prompt, so caching can be done at the MCP level itself.
At this point, it's not just about caching for identical prompts — I understand there's also an approach using semantic caching to cache semantically similar content. It calculates semantic similarity, vectorizes it, and embeds it. When new input comes in, it's similarly vectorized, and if it's similar to the embedded data, the corresponding response is returned. But thinking about implementing this myself gives me a headache. I don't want to know anymore.
Anyway, the point I'm trying to make is that if existing remote server API providers (today's server developers) start providing MCP servers as well, choosing the right caching strategy has become important in this new era. Rather than the mindset of "I'll trust the remote server-side caching and handle the flood of traffic with a fancy server architecture!", you need to consider adding in-memory caching at the MCP server level to reduce the traffic hitting the remote server.
But then again, if the business model charges users based on remote server API call volume, they might intentionally not add caching to the MCP server. From the user's perspective, it might be better to use a caching MCP server that caches all the calls from MCP servers acting as API call bridges.
2. Request Throttling
As I mentioned above, once you start using MCP, the LLM doesn't just take in a single line of prompt — it interprets that prompt and starts calling multiple external APIs all at once.
Before, users called APIs directly, so you could somewhat predict "how many requests they'd send at once" and "how long execution would take." But an LLM might chain 5, 10, or even more requests just to fulfill a single sentence's objective.
a. Rate Limiting
The problem is that traditional remote server APIs have rate limiting restrictions — things like "don't send more than 3 requests per second." So when making API calls from the MCP server, you need to account for rate limiting. (It feels like we're taking the concerns that traditional clients used to deal with and baking them into the MCP server.)
The MCP server above is actually designed to visualize using the Qlik Cloud API, and if you look at the actual call code, you can see a delay applied for rate limiting.
const data = await withRetry(async () => chartObject.getHyperCubeData('/qHyperCubeDef', [{
qTop: startRow,
qLeft: 0,
qWidth: metadata.totalColumns,
qHeight: rowCount
}]));
if (data?.[0]?.qMatrix) {
allData.push(...data[0].qMatrix);
}
// Add delay between chunks to avoid rate limiting
if (startRow + pageSize < rowsToFetch) {
await delay(REQUEST_DELAY_MS);
}
The rate limiting code was inside the pagination for-loop.
Other things worth considering include:
b. Timeout
If the MCP server keeps calling external APIs but the responses are coming back too slowly, it's good to set proper timeouts to force-terminate and guide the LLM to produce results using other MCP tools instead.
c. Concurrency Limits
When the LLM fires off multiple requests in parallel using MCP tools, the impact on the remote server grows accordingly. Even with the rate limiting from section (a), you can see the code only applies rate limiting to individual API requests. However, since MCP can use multiple tools simultaneously to make API requests, running several tools at once could cause a burst of load on the remote server all at once.
So in Java, for example, you'd use an ExecutorService with a fixed thread pool to control the number of concurrent tasks when making API calls.
d. Circuit Breaker
What if your remote server is down but the LLM keeps making the MCP retry? Requests pile up on the remote server, and if the concurrency limits from section (c) are also in place, you could end up in a situation where resources can't be utilized at all. To prevent this, you may need logic that blocks API calls after a certain number of failures.
When I step back and look at what I've written, doesn't implementing an MCP server feel like providing both a server and a client at the same time? To integrate an MCP server into an existing system, it feels like you just need to apply all the performance tricks that used to live on the client side to the MCP server instead.
3. Security
This one scares me the most.
4. Technology Evolves, but the Fundamentals Stay the Same
Ever since LLMs came out, I keep hearing "aren't developers going to be out of a job?" First of all, looking at MCP by itself, it's just a new form of API protocol. API requests just got closer to natural language, that's all.
So just because the requests coming from the frontend are now in natural language doesn't mean the server's role in processing them disappears. If anything, it means users can now make requests more conveniently.
At the end of the day, to build a service you still need to design specific flows, add caching for security and performance, and distribute traffic. This is the same work developers have always done.
Back when we transitioned from the PC-only era to the mobile era, the concept of servers already existed. But with mobile, those servers started receiving requests from multiple environments, access became easier, and the volume of requests servers had to handle skyrocketed. So server developers racked their brains to propose various methodologies for performance improvement and came up with architectures leveraging existing concepts — isn't that what happened?
Now, as we transition from the mobile app era to the era of receiving services through LLMs, it's almost identical to before. Just like before, as it becomes easier for users to make server requests, servers willfocus even more on performance improvements, and architectures leveraging existing concepts around client-server communication and security will emerge, along with even more efforts to push server performance further.
So developers aren't disappearing — rather, we should be growing into developers who can fill these gaps. Ultimately, won't developers who deeply understand the fundamentals of existing technologies be the ones needed even more in the LLM era? So I've arrived at the conclusion that... we still need to study development after all..
The end.
But honestly, I can't write blog posts with GPT. The stuff it writes is just too cringe.
진짜 오랜만에 올리는 포스팅..ㅎㅎ 민망하구만. 24년 6월부터 7월까지 한 달 반의 시간동안 평일 저녁과 주말 시간을 쪼개서 Google Gemini API Developer Competition (Gemini API를 사용한 제품 개발 공모전)에 참여했다. 1명의 PM, 2명의 클라이언트개발자, 1명의 디자이너, 그리고 서버개발자였던 나. 능력있는 멋진 동료들과 함께해서 그런지 힘든 기억보단 새로웠던 시간들이라 블로그로 정리하게 되었다.
어느덧 카카오에 입사한지 4년이 되었는데 (5년차라니...) 회사 일에 적응하고 외부 활동은 거의 안하다보니 슬슬 갇혀있는 기분이 들었었다. 회사에서 하는 AI 수업도 들었는데 결국 하는 일은 비슷비슷하다보니 요즘 세상은 어떻게 돌아가는지가 궁금했었다. (회고라 쓰고 외부 개발세계 탐방기라고 읽는다) 그러던차 PM 언니한테 생일 축하 메시지와 함께! 같이 공모전 할 생각있냐는 연락이왔다..!!!
회사 일에 지장이 될까 걱정됐는데, 현생에 방해되지 않게 책임진다는 말과 클라이언트 개발자 분의 계획이 담긴 카톡을 보내줬는데 너무 든든해서 결국 참가하게 되었다. 기존 코드 고치는 작업이 아니라 내가 처음부터 코드를 짜는게 얼마만인지 두근두근!!
사전 지식 준비 (gen ai, spring-ai)
Gemini API를 사용해서 프로젝트를 제출하는 거였는데, 사실 굉장히 시기가 좋았다. 마침 회사에서 Generative AI(이하Gen AI) 기초반, 심화반 강의도 신청해서 듣고 흥미가 생겼었기 때문이다. AI 개발의 경우엔 대학때부터 느꼈지만 되게 나랑 안맞았다. 왜 그게 그 결과가 나오는지 이해가 안되서인가... 납득이 잘 안됐다. 근데 GPT가 나오고 언젠가는 결국 해야할 것들이라는 생각이 들어서 한번 공부를 하면 좋겠다 싶어서 회사 세션을 시작하게되었고 이 공모전을 시작하게되었다.
대부분의 사이드프로젝트가 그렇듯 사실 클라이언트만 있어도 결과물이 나오는데 서버가 굳이..? 싶었는데, 아무래도 클라에서 하면 API나 프롬프트가 외부에 노출될 가능성도 있고, 개선시 클라이언트 패치의 불편함이 있어서 서버개발자를 구하게 되었다고 하셨다.
사실 서버는 Gen Api 호출 서버를 만드는거라서 간단했다. 그래서 이참에 Spring-AI를 사용해보자는 개인 목표를 잡으며 공모전에 참여하게 되었다.
우선적으로 회사를 통한 gen ai 공부는 꽤나 신기했다. 여러 개념이나 모델에 대한 설명에서 시작해서 프롬프트 엔지니어링, RAG, ollama, langchain, function call 실습 등 전반적인 방향성을 잡는데 도움이 되었다. 따라서 우리 공모전에서 AI를 사용할때 어떤 선택지가 있는지를 고를 수 있는 기반이 되었던 것 같다. 그리고 끝나고 팀원분들께 간단 공유시간도 가졌었는데 지금 몇개월 지나니까 다시 기억이 잘 안나는 것 같기도..
덕분에 우리 공모전에서 필요했던 건 RAG까지 갈 필요도 없이 prompt enginneering 만으로도 충분히 가능하다는걸 이해할 수 있었고, 사실 prompty engineering만 한다면 spring자체에서만 보면 httpClient 만 있어도 괜찮다는걸 스스로도 알았다. 그치만 spring-ai를 써보고싶었고, 오히려 spring-ai를 쓰면서 여기서는 지원하지 않아 생긴 허들도 있었어서 재밌었다. (이건 아래에) spring-ai를 쓰다보니 아직 안정화가 되지않아 구조가 휙휙 바뀌는 프레임워크단 코드를 체감할 수 있었던게 회사에서와는 다른 경험이라 신기했다.
우리팀의 핵심 기능은 gemini prompt와 대화하며 일기를 적거나 글로 하루를 회고한 내용을 바탕으로 youtube music을 추천하는걸 주 기능으로 하는 앱이다. 제목은 muse diary 이다. gemini가 추천해주는 음악이 당신의 일상에 한번 더 영감을 주면 좋겠다는 의도로 muse라는 단어가 떠올랐다. 아무래도 gen ai를 사용한다면 이미 검색으로 찾을 수 있는 public한 내용에 대한 정리집 혹은 커뮤니티성 앱보다는 개인화에 집중된 private한 내용이 좀 더 사용성에 맞는 것 같다고 팀원간의 의견 나눔이 있었다.
짱 멋진 팀원들 자랑
1. 기획
초반에는 기획을 다같이 정리하는 시간을 가졌는데 PM언니가 떠다니기 쉬운 아이디어들을 잘 정리해주고 다시 리마인딩 하면서 회의를 진행했던게 좋았다.
커뮤니케이션은 보통 슬랙으로 했었는데, 평소에 업무를 할 때 카톡으로 하다보니 슬랙 확인을 좀 늦게하곤했었다ㅠ 그런데 확실히 회사밖의 다른 개발자들은 슬랙을 잘 쓰는구나 싶어서 되게 재밌었다. 퇴근하고 아무래도 밀려있는 내용들을 볼때 언급되어있는 스레드들 모아보기로 빠르게 확인하고 개발하고 배포해서 빠르게 확인하는게 되게 효율적이었다.
간만에 회사 외부의 능력자들과 일하는 경험이 되게 신선하면서도 서로 현생에 영향을 미치지 않게 배려해줘서 무사히 마칠 수 있었다.
2. 디자인
항상 나는 디자이너분들을 되게 좋아하는 편인데 (클라 개발자가 아니라 부딪힐일이 없어서그런가) 이번에도 역시 디자이너 너무좋다 디자인이 이뻤다!!! 하루를 마치고 LP바에서 술한잔과 함께 오늘 있었던 일을 얘기하면 그에 맞는 잔잔한 노래를 듣는 느낌을 생각했는데, 바이닐 컨셉의 디자인을 가져와주셨다.
다들 직장인이라 바쁜 시간을 쪼개서 참여하다보니 사실 아이디에이션 했던 모든 기능을 넣을수가 없었는데, PoC단계에서 GUI 디자인 단계로 넘어가기 직전에 대부분의 앱들에서 사용하는 탭바를 걷어내자고 디자이너분이 제안을 주셨다. 덕분에 핵심기능에 집중해서 공모전을 마무리할 수 있었다. (기한이 쫄린다면 기획을 쳐내는게...) 다들 현생을 놓지않으면서도 새벽시간을 쪼개서 얘기하고 회의하고 밥먹고 되게 기억에 남는 팀이 될 것 같다.
클라이언트 개발자 두 분은 플러터로 개발을 했었는데, 확실히 크로스 플랫폼의 이점이 있었다. gen ai 프롬프팅을 한 클라개발자분께서 담당하셨었는데 (너무 감사했다.. 백엔드지만 프롬프팅 엔지니어링 까지는 관심이 없었기에 ) flutter로 프롬프팅 관련 PoC를 금방 구현해보시더니 다른 팀원분들도 해보라고 web으로 배포해서 주셨다. 덕분에 일기 추출 프롬프팅 부분을 다같이 테스트해보며 실제로 gpt가 말하는 뉘앙스를 보며 프롬프트를 수정하기도하고, 앱의 디자인적 사용성이나 백엔드에서는 실제로 들어갈 데이터들을 좀 더 고려해 볼 수 있었다.
그리고 클라이언트 각종 인터렉션을 디자인적 완성도를 위해 깡코드로 구현하시고, 많이 있는 library를 쓰지 않고 직접 코드로 구현한다거나.. 이런 부분이 개인적으로 가장 놀라웠다. 바이닐을 넘기는 인터렉션을 하나하나 디자이너분께 컨펌받으면서 섬세하게 디테일을 잡으시는 모습도 인상적이었고, 나는 백엔드 개발자다보니 당연히 달력은 라이브러리를 쓴다는게 고정적인 생각이었어서 그런가 직접 달력부분 코드를 하나하나 짠다는것도 충격이었다.
그리고 실제로 보내주신 코드들을 보니 다트가 깔끔한건지 코딩을 잘하신건지.. 보기에도 편했다. 시니어 클라이언트 개발자와 함께하는 사이드프로젝트 꽤나 감격적이었달까
서버만 잘하면 되겠네
그래서 이렇게 자기할일 딱딱하는 팀원들과 함께 하기위해서라면 나도 일을 착착 해나가야겠다! 싶었는데 회사 밖에서 코딩을 한다는건 코딩이 문제가 아니었다! 그동안 기본적으로 환경세팅이 다 되어있던 회사 인프라를 벗어나서 외부에서 하나하나 해야하는 상황! 되게 재밌었다 외부 생태계는 이렇구나 요즘 개발자들은 이렇게 개발하는구나를 체험해볼수있어서 디버깅을 하나하나 해나가는게 재밌었다. 퇴근하고 정신없이 코딩하는게 그냥 며칠만 투자하면 됐기 때문에, 금방금방되서 그런가 몇개월이 지난 지금 생각해도 힘든것보단 재밌었다는 기억만 남았다!!!
코딩보다도 CI/CD구성이나 환경변수 관리 새로운 인프라 api에 대한 러닝커브 등등이 좀 더 기억에 남는다. 사실 사이드 프로젝트다 보니까 api 서버 만드는 건 확장성보다도 기획에서 바로바로 요청이 올 때 빠르게 변경한다거나 이런것들이 더 중요했기 때문에 객체화 클린코드 테스트코드 같은 것 보다 가장먼저 CI/CD부터 완성했다.
1. github Action CI/CD
회사에서는 CI/CD를 jenkins로 하고있어서 github action을 처음써봤다. github action에 대해서 좋다고 좋다고 말만들었지 처음 써보는거라 ansible 문법 익히듯이 action 문법들을 익혀야하는건가 싶었는데와 요즘 개발은 GPT를쓰는구나?
진짜 감격 그자체 dockerfile 부터 github action worflow까지 다 짜주는 이런 세상이라니.. 그래서 action 쓰기는 했지만 썻다고 말할수 없다 내가 만든게 아니라 gpt가 만들었으니까! 근데 사실 여타 ci/cd가 그렇듯 jenkins pipeline문법이나, ansible 문법이나 action 문법이나 그냥 찾아가면서 작성하는거니까.. 라고 생각하면서 패스했다.
회사에서는 아무래도 소스코드나 에러메시지를 직접 복사 붙여넣기해서 넣지 못하다보니 gpt한테 질문할때 가공해서 넣어야해서 귀찮았었는데 그냥 넣으면 나오니까 편했다ㅋㅋ. 그리고 Google Cloud Platform을 쓸때도 어떤 버튼을 어떤메뉴에 들어가야하는지까지 알려주고 바깥 세상 개발은 참 좋구나... 회사 내부 인프라를 사용하다보면 내부 인프라 가이드를 찾아보고 그랬었는데, 외부 세상에서 하는 개발은 gpt한테 물어볼 수 있다는 메리트가 있었다. 그동안 회사 개발만 했다는 티가 너무나나ㅠㅠ
그러나 바깥 세상의 개발중에 언제나 그렇듯 귀찮았던건 아무래도 secret 관리였다. 회사안에서는 사실 priavet repository라서 일부는 springboot aplication.yml에 박아서 썼었는데 각종 변수 하나하나를 환경변수 처리를 해야한다니.. 그리고 안했을때 혹시라도 과금폭탄이 무서웠다. 물론 private repository를 쓰면 똑같지만 공모전이다보니 open source 여야했다.
이런 민감정보들이 몇개 되지는 않아서 우선은 전부 app 시작시 쓰는 환경변수로 처리했는데, 만약 프로젝트가 좀 더 커진다면 좀 귀찮아 질 것 같다. 그치만 application.yml 파일 자체를 직접 import해서 로딩한다던지 다른 배포방법도 있지 않을까 싶긴하다. 이런 환경변수 처리들을 좀 쉽게하는 오픈소스들이 무조껀 있을텐데.. 라는 생각이 들면서도 개발을 시작해야하다보니 우선은 github action 자체의 secret을 사용했다.
그리고 사실 엄청 간단한 CI/CD 였기 때문에 문법이나 플러그인을 새롭게 도입할 필요가 없었다. 그래서 오히려 github CI/CD 예제를 보고 배포 플랫폼을 정했다ㅋㅋㅋ gemini api를 써야하다보니 Google Cloud Platform을 무조껀 써야하는 상황이었다. 따라서 google기반의 작은 vm기반 서버로하면 돈이 덜 들테니 그렇게 할까는 막연한 생각만 있었는데, action workflow을 쳐보니 cloud run 이란게 있네..? 부터 시작해서 위와 같은 서버 구조를 갖게 되었다. GKE는 쿠버네티스니까 스케일업,아웃 헬스체크까지 필요한 오케스트레이션 스펙은 현재 굳이 쓸 필요가 없다고 판단했다.
딱 빌드한 이미지가 빠르게 즉각적으로배포되면서, 작은 컴퓨팅 리소스만 쓰는게(replica를 1로 설정했다.) 이런 작은 공모전 프로젝트에 오히려 적합하다는 생각이 들었다. 이런 gcp사용도 하나의 러닝커브였는데 이것 역시 GPT가 친절하게 어떤 버튼을 누르면 되고,, 어떤버튼으로 설정하면 되는지 알려주는 친절한 외부 개발 세상에 감탄했다ㅋㅋㅋ
그렇게 만든 github action flow는 아래와 같이 매우 간단하다 (여러 account key, secret 전달로 인해 길어졌을뿐.)
cloud run을 사용하니 로깅도 즉각적으로 확인 할 수 있고 트래픽 모니터링도 기본적으로 제공해주는 게 있어서 편했다. (알람 시스템까지 따로 달았다면 좀 더 즉각적으로 에러를 볼 수 있었겠지만... 현재 사용자도 없는데 오버스펙이다.)
2. Spring + Kotlin 개발 그리고 Spring-Ai
그리고 이제 내부 api를 개발할 때가 되었는데 사실 인증, 데이터베이스, ai 사용. 이렇게 세가지가 주요한 백엔드 기능이었다. gemini 개발자 대회에서 firebase 섹션도 있어서, 인증과 데이터베이스를 모두 firebase 기반으로 구현했다. firebase관련 코드자체는 클라이언트 사이드에서 직접쓰면 좀 더 효율적이었을 거란 생각이 들긴했다. firebase 코드전부가 future로 되어있었는데 spring-webflux도 아니라 spring-mvc 기반으로 사용하고있어서 전부 blocking하게 데이터를 가져올 때 조금 아쉬움이 들었다.
간만에 사용하는 spring-security로 firebase token 기반 인증을 구현하였고, database는 전부 cloud firestore로 구현했다. 그리고 gemini api 호출부는 spring-ai 기반으로 구현하였다. 비즈니스로직이 사실상 db읽기 + gemini api 호출뿐이라 큰 복잡도가 없어 model이 중요한 상황에서 kotlin을 사용하니까 data class를 사용하는게 코드 줄수도 적고 편했다.
이 공모전을 시작하면서 spring-ai를 쓰는게 목표였는데 사실 우리팀의 경우엔 RAG이나 embedding model을 커스텀해서 쓰기보단 gemini api에 호출하고 호출할때의 prompt engineering을 잘 하는게 목표였기 때문에 spring-ai 안에서도 chatClient만을 사용했다. chatClient에서 제공하는 기능을 사용하는건 사실상 httpClient로도 가능하지 않나 싶어서 조금 아쉬운 부분이었다.
그래도 spring-ai덕분에 python 환경에서 langchain, lamaindex를 사용할 때 공통된 포맷으로 gen ai api를 호출하고 embedding model을 변경하는 등의 작업을 할수 있다는 것처럼, jvm 시스템 안에서도 이런 일들이 조금은 가능하다는점에 의의가 있다고 생각했다. 따라서 Spring-AI의 경우에 ChatClient를 기반으로하는 추상화가 중요했고, Gpt, VertexApi, Azure 등등의 gen ai 모델들을 ChatModel들의 구현체들로 유연하게 사용할 수 있게 했다는 점에서 객체지향을 많이 고려한다는게 느껴졌다.
다만 각 gen ai 모델 구현체들의 업데이트도 빠르게 이루어지고 지원범위가 다양하게 있는 만큼, 그걸 spring-ai 에서 따라가기 힘든경우가 있구나 느꼈는데 그것또한 되게 재밌는 경험이었다.
vertex api 스펙에 보면 response의 출력형식을 결정할 수 있는 요청 필드가 있는데 이 필드가, VertexAiGeminiChatModel 에서는 구현이 되어있지 않은 상황이었다. 우리 공모전에서 사용할 prompt에서는 이 필드를 꼭 넣어야 json 타입으로 응답이 올바르게 오는데 지정을 하지 않으면 parsing 에러로 500에러가 간간히 떨어지는 경우가 있었다.
따라서 이걸 spring-ai의 chatClient를 안쓰고 그냥 httpClient를 사용해서 해결할까..라는 고민을 하다가 이미 어느정도 ChatClient에 맞춰서 개발을 해둔 상황이었고, spring-ai의 공식지원은 아니지만 reflection을 이용해서 config를 직접 주입해 넣으면 될것 같아서 아래와 같이 VertexAiGeminiChatModel의 기본 구현을 무시하고 reflection으로 내가 원하는 기능을 구현했다.
val chatModel = VertexAiGeminiChatModel(
VertexAI(System.getenv("GEMINI_PROJECT_ID"), System.getenv("GEMINI_LOCATION"))
)
val generationConfig = GenerationConfig.newBuilder()
.setResponseMimeType("application/json") // responseMimeType 을 설정할 수 없어서. 직접 접근하여 설정하였다.
.setTemperature(0.8f)
.build()
val generationConfigField = VertexAiGeminiChatModel::class.java.getDeclaredField("generationConfig")
generationConfigField.isAccessible = true
generationConfigField.set(chatModel, generationConfig)
생각해봤을때 spring-ai에서 default로 제공하는 gemini 버전은 gemini-1.5-pro 였고, 이 요청필드의 경우엔 1.5부터 지원을 했기에 공식적으로 지원을 하는게 좋지 않을까 싶어서. spring-ai에 해당 필드를 추가하여 PR도 넣어보았는데 승인되었다 :) 공모전덕분에 spring 관련 레포에 처음으로 contribution 하는 경험을 얻었다.
CI/CD를 완성하면서 인증, 데이터베이스, gen ai 호출까지 왠만한 기능들의 api를 구현하는것만 남았었다. 처음부터 swagger는 붙였었지만 실제로 해당 api를 사용할때 파라미터는 어떻게 해야하고, 어떤의미이고 이런것들을 처음엔 거의다 slack으로 안내를 드렸다. 근데 하다보니.. 같이 작업하시는 클라이언트 개발자분들의 편의가 걱정이 되었고 이에 따라 swagger에 documentation을 제대로 달아서 소통을 하는 방향으로 작업 방향을 바꾸게 되었다.
그런데 이런부분을 되게 좋아하셨어서 다음에 또 사이드프로젝트를 하게된다면 그때는 swagger기반으로한 문서화를 기본으로하고, 스웨거에서 api 호출도 가능하게까지 지원해야겠다고 생각했다. spring-security + swagger를 같이 사용하면 그만큼 스웨거를 이용한 api 호출을 이용할 때 추가 설정을 해줘야하는데, 허허 퇴근후 개발 쉽지않다더라.
마치며
회고이기 때문에 내가 느낀점들을 위주로 글을 흐물흐물 쓴거같다. 그동안 퇴근하면 운동하고, 친구들 만나던 삶을 반복하다가 간만에 개발을 하다보니 리프레쉬가 되던 경험이었다. 스펙을 간단하게 잡기도했고 아무래도 서버사이드에서 크게 챌린징할만한 부분이 없었던(?) 작고 소소한 개발이었을지라도 퇴근하고 시간을 쪼개서 작은 프로젝트를 좋은 사람들과 협업해서 만들었다는게 되게 기분이 좋았기 때문에 간만에 블로그를 쓰게 되었다.
사실 아쉬운건 언제나 있을 수 밖에 없다.사이드 프로젝트다 보니 코드를 너무 일회성으로 짜버렸을까. spring-ai 사용할때 테스트코드도 한번 짜볼껄, 슬랙으로 알람 연결해서 클라 개발자분들의 제보없이도 빠르게 고칠 수 있게 만들어볼껄 그랬나. 가장 간단한 인증방식으로 우선 구현을 위해서 했는데 jwt 기반으로 해볼껄 등등 여러가지 생각나는 것들이 있긴하다.
또한 서버에서 챌린징하는건 아무래도 정말 운영환경에 들어갔을때 정말 일이 시작되는구나도 느끼게되었다. 사실 api를 개발하는건 어떤 개발자든 금방 할테지만, 그 api를 얼마나 확장성있게, 그리고 안전하게, 빠르게 탐지하고 운영할 수 있게 만드는건 더더욱 중요한 요소라는 걸 반증하는 것 같았다. 놀랍게도 그래서 사이드 프로젝트를 하면서 회사 내부에서 사용하는 여러 운영 스킬들에 대해서도 한번 더 중요함을 느끼게되었다.
여튼 주절주절은 여기서 끝! 혹시라도 읽으시는 분이 있다면 현재 피플스초이스어워드가 진행중이니, 소중한 한표 부탁드립니다~! 🙇♀️
It's been so long since my last post..haha, kind of embarrassing. From June to July 2024, over the course of about a month and a half, I squeezed in weekday evenings and weekends to participate in the Google Gemini API Developer Competition (a competition for building products using the Gemini API). Our team consisted of 1 PM, 2 client developers, 1 designer, and me — the server developer. Working with such talented and awesome teammates made it more of a refreshing experience than a tough one, which is why I decided to write this blog post.
Before I knew it, it's been 4 years since I joined Kakao (year 5, seriously...). After getting comfortable with work and barely doing any outside activities, I started feeling a bit trapped. I even took AI classes offered by the company, but at the end of the day, the work stayed pretty much the same, so I was curious about what's going on in the world these days. (It says retrospective but really it's an exploration journal of the external dev world.) Then, out of the blue, my PM sent me a birthday message along with — surprise! — an invitation to join a competition together..!!!
I was worried it might interfere with my day job, but she promised it wouldn't get in the way of our real lives, and one of the client developers sent over a detailed plan via KakaoTalk — it was so reassuring that I ended up joining. It had been so long since I wrote code from scratch instead of fixing existing code — I was excited!!
Background Knowledge Prep (Gen AI, Spring-AI)
The competition was about submitting a project using the Gemini API, and honestly, the timing couldn't have been better. I had just signed up for and attended the Generative AI (Gen AI) beginner and advanced courses offered by my company, which had sparked my interest. When it comes to AI development, I've felt since college that it really wasn't my thing. Maybe it's because I couldn't understand why certain results came out the way they did... it just didn't click. But after GPT came out, I started thinking it was something I'd eventually have to tackle, so I figured I should study up — that's how I started the company sessions and eventually this competition.
Like most side projects, the client side alone could produce a working result, so you might wonder — do we really need a server? But having everything on the client side could expose the API keys and prompts, and pushing client patches for every improvement would be inconvenient, which is why they decided to bring in a server developer.
The server work was actually pretty straightforward since it was basically building a Gen AI API calling server. So I set a personal goal of using Spring-AI for this opportunity and joined the competition.
The Gen AI study through the company was quite fascinating. Starting from explanations of various concepts and models, it covered prompt engineering, RAG, Ollama, LangChain, function call hands-on practice, and more — it really helped me get a sense of the overall direction. It became the foundation for understanding what options we had when using AI in our competition project. I even held a brief sharing session with my teammates afterwards, though now that a few months have passed, I'm not sure I remember everything that well..
Thanks to that, I was able to understand that what we needed for our competition didn't even require RAG — prompt engineering alone was more than enough. And honestly, if it's just prompt engineering, even a plain httpClient would do the job from a Spring perspective. But I wanted to try Spring-AI, and the hurdles that came from things it didn't support yet actually made it fun. (More on that below.) Using Spring-AI, I got to experience firsthand how a framework that hasn't stabilized yet goes through rapid structural changes — something quite different from what I'm used to at work, which was pretty cool.
Our team's core feature was an app whose main function is to recommend YouTube Music based on diary entries written through conversation with a Gemini prompt, or based on written reflections about your day. The title is Muse Diary. The word "muse" came from the idea that the music recommended by Gemini could inspire your daily life once more. When using Gen AI, we agreed as a team that it makes more sense to focus on personalized, private content rather than building a compilation or community-style app for publicly searchable information.
Shoutout to My Amazing Teammates
1. Planning
In the early stages, we all spent time organizing the plans together, and our PM did a great job of wrangling all the floating ideas, keeping things organized, and reminding everyone during meetings — that was really helpful.
We mostly communicated via Slack, but since I normally use KakaoTalk for work, I tended to check Slack a bit late 😅 But it was really interesting to see how developers outside my company actually use Slack well. After getting off work, being able to quickly catch up on piled-up messages through the thread mentions view, then code and deploy — it was really efficient.
Working with talented people outside of my company after such a long time was really refreshing, and everyone was considerate about not letting it affect each other's real lives, so we managed to wrap things up smoothly.
2. Design
I've always been a big fan of designers (maybe because I'm not a client developer so there's nothing to butt heads about?), and this time was no different — the designer was amazing and the design was beautiful!!! I had imagined the feeling of finishing your day at an LP bar, having a drink, and talking about what happened while listening to some mellow music — and the designer brought exactly that with a vinyl concept.
Since everyone had full-time jobs and was squeezing in time to participate, we couldn't actually include every feature we ideated. Right before moving from the PoC stage to the GUI design phase, our designer suggested removing the tab bar that most apps use. Thanks to that, we were able to focus on the core features and wrap up the competition. (When the deadline is tight, cutting features from the plan is the way to go...) Everyone managed to not abandon their real lives while still squeezing in late-night discussions, meetings, and meals together — I think this team will stay in my memory for a long time.
The two client developers built with Flutter, and the cross-platform benefits were definitely real. The client developer who handled the Gen AI prompting was in charge of that part (I was so grateful.. as a backend developer, prompt engineering wasn't really my area of interest) — they quickly built a prompting PoC in Flutter and even deployed it as a web app so the rest of the team could try it out. Thanks to that, we were all able to test the diary extraction prompting together, see the nuances in how GPT responds, tweak prompts accordingly, and better consider the app's UX as well as the actual data that would flow through the backend.
And the client developers implemented various interactions from scratch for design completeness, opting to write the code themselves instead of using commonly available libraries.. that part personally impressed me the most. Watching them meticulously fine-tune the vinyl-flipping interactions one by one while getting confirmation from the designer was also really impressive. As a backend developer, I always assumed calendar components would naturally come from a library, so the fact that they hand-coded the calendar from scratch was honestly shocking to me.
And looking at the code they shared, whether it's Dart that's clean or they're just great coders... it was really easy to read. Working on a side project with senior client developers was quite a moving experience, I'd say.
All I Need to Do Is Handle the Server, Right?
So with teammates like these who just get their stuff done, I felt like I needed to step up too! But coding outside of work turned out to be — the coding wasn't the hard part! Breaking out of the company infrastructure where everything was already set up, and having to do everything from scratch on my own! It was actually really fun. Experiencing the external ecosystem and seeing how developers work these days — debugging things one by one was enjoyable. Coding frantically after work only needed a few days of investment, so it flew by quickly. Even now, months later, the memories that stick are the fun ones, not the tough ones!!!
What stuck with me more than the actual coding was setting up CI/CD, managing environment variables, and the learning curve for new infrastructure APIs. Since it was a side project, building the API server was less about scalability and more about being able to quickly make changes whenever requests came in from the planning side, so rather than focusing on object-oriented clean code and test code, I completed the CI/CD first.
1. GitHub Actions CI/CD
At work, we use Jenkins for CI/CD, so this was my first time using GitHub Actions. I'd only ever heard people say how great it was but never actually used it. I was thinking I'd have to learn the Actions syntax like learning Ansible syntax, but then — wow, so nowadays people use GPT for development?
I was genuinely amazed — we live in a world where it writes everything from the Dockerfile to the GitHub Actions workflow for you.. So I did use Actions, but I can't really say I "wrote" it since GPT did it for me! But honestly, like any CI/CD tool, whether it's Jenkins pipeline syntax, Ansible syntax, or Actions syntax, you just look things up as you go.. that's what I told myself and moved on.
At work, since I can't directly copy-paste source code or error messages, I had to sanitize things before asking GPT, which was annoying. But here, I could just paste it in and get answers right away lol. And when using Google Cloud Platform, it even tells you which button to click and which menu to navigate to — developing in the outside world is really nice... When you're using internal company infrastructure, you have to dig through internal infra guides, but in the outside world, you have the perk of being able to ask GPT. It was so obvious that I'd only been doing company development until now 😢
However, as always in the outside development world, the annoying part was definitely secret management. At work, since we use private repositories, I'd sometimes just hardcode things in the Spring Boot application.yml — but having to turn every single variable into an environment variable.. and the fear of getting hit with a billing bomb if I didn't. Of course, using a private repository would be the same, but since it was a competition, it had to be open source.
There weren't that many sensitive values, so I handled them all as environment variables loaded at app startup. If the project were any bigger, it would've gotten pretty tedious though. That said, there are probably other deployment approaches like directly importing and loading the application.yml file itself. I had a feeling there must be open-source tools out there that make environment variable management easier.. but since I needed to start developing, I just went with GitHub Actions' built-in secrets for now.
And since the CI/CD was really simple, there was no need to learn new syntax or adopt plugins. So I actually chose the deployment platform based on GitHub CI/CD examples lol. Since we had to use the Gemini API, we were basically required to use Google Cloud Platform. I had a vague idea of using a small VM-based server on Google to keep costs down, but when I looked up Action workflows, I found this thing called Cloud Run..? — and that's how we ended up with the server architecture above. I decided GKE was overkill since it's Kubernetes with orchestration specs for scale-up/out and health checks that we didn't need at the moment.
It felt perfect for this kind of small competition project — the built image gets deployed immediatelywhile using minimal computing resources (I set replicas to 1). Learning to use GCP was another learning curve, but once again, GPT kindly told me which buttons to click and which settings to configure — I was impressed by how friendly the outside development world is lol
The resulting GitHub Actions flow is super simple as shown below (it just looks long because of all the account keys and secret passing).
Build the Dockerfile (the Docker build runs a Gradle build to start the app).
Push the Docker image to the GCP registry.
Cloud Run runs the pushed image (with replica 1).
Using Cloud Run, I could check logs in real time and it came with built-in traffic monitoring, which was convenient. (If I had set up an alert system, I could have caught errors even more quickly... but with no actual users, that would be overkill.)
2. Spring + Kotlin Development and Spring-AI
Then it was time to develop the internal APIs, and the three main backend functions were essentially authentication, database, and AI usage. Since the Gemini developer competition had a Firebase section too, I implemented both authentication and database using Firebase. In hindsight, the Firebase-related code might have been more efficient if used directly on the client side. All the Firebase code was based on futures, but since I was using Spring MVC rather than Spring WebFlux, I felt a bit disappointed having to fetch everything in a blocking manner.
I implemented Firebase token-based authentication using Spring Security (which I hadn't used in a while), and the database was entirely built on Cloud Firestore. The Gemini API call layer was implemented using Spring-AI. Since the business logic was essentially just DB reads + Gemini API calls with no major complexity, and the model layer was what mattered most, using Kotlin's data classes kept the code concise and convenient.
My goal going into this competition was to use Spring-AI, but in our team's case, rather than customizing RAG or embedding models, the goal was to call the Gemini API and do good prompt engineering. So within Spring-AI, I only used the ChatClient. Using the features provided by ChatClient felt like something that could've been done with just an httpClient, which was a bit underwhelming.
Still, thanks to Spring-AI, just as LangChain and LlamaIndex in the Python ecosystem allow you to call Gen AI APIs in a common format and swap embedding models, I thought it was meaningful that similar things are now somewhat possible within the JVM ecosystem too. So the key abstraction in Spring-AI was centered around ChatClient, and the fact that it enables flexible use of various Gen AI models — GPT, Vertex API, Azure, etc. — through implementations of ChatModel showed that a lot of object-oriented thinking went into it.
However, since each Gen AI model implementation updates rapidly and supports a wide range of features, I noticed that Spring-AI sometimes struggles to keep up — and that was actually a really interesting experience.
Looking at the Vertex API spec, there's a request field that lets you determine the output format of the response, but this field wasn't implemented in VertexAiGeminiChatModel. In our competition, we needed this field to ensure the response came back properly in JSON format — without specifying it, we'd occasionally get 500 errors from parsing failures.
So I debated whether to ditch Spring-AI's ChatClient and just use httpClient instead, but since I'd already built a fair amount around ChatClient, and I figured I could inject the config directly using reflection even though it wasn't officially supported by Spring-AI, I ended up bypassing VertexAiGeminiChatModel's default implementation with reflection to implement the feature I needed, as shown below.
val chatModel = VertexAiGeminiChatModel(
VertexAI(System.getenv("GEMINI_PROJECT_ID"), System.getenv("GEMINI_LOCATION"))
)
val generationConfig = GenerationConfig.newBuilder()
.setResponseMimeType("application/json") // responseMimeType 을 설정할 수 없어서. 직접 접근하여 설정하였다.
.setTemperature(0.8f)
.build()
val generationConfigField = VertexAiGeminiChatModel::class.java.getDeclaredField("generationConfig")
generationConfigField.isAccessible = true
generationConfigField.set(chatModel, generationConfig)
When I thought about it, the default Gemini version provided by Spring-AI was gemini-1.5-pro, and this request field was supported starting from version 1.5, so I thought it would be good for them to officially support it. I submitted a PR to Spring-AI adding this field, and it got approved :) Thanks to the competition, I got the experience of making my first contribution to a Spring-related repo.
After finishing the CI/CD, all that was left was implementing the APIs for authentication, database, and Gen AI calls. I had attached Swagger from the start, but when it came to actually using those APIs — what parameters to send, what they meant — I initially communicated almost everything through Slack. But as I kept going, I started worrying about the convenience of the client developers I was working with, so I shifted my approach to properly documenting everything in Swagger for communication.
They really appreciated it, so if I ever do another side project, I plan to make Swagger-based documentation the default from the start, and even support making API calls directly from Swagger. When you use Spring Security + Swagger together, you need additional configuration to enable API calls through Swagger, and well, developing after work isn't easy, let me tell you.
Wrapping Up
Since this is a retrospective, I think I've been rambling on about my personal thoughts and feelings. After months of the same routine — working out after work and meeting friends — getting back into development after such a long break was really refreshing. Even though the spec was kept simple and there wasn't much that was deeply challenging on the server side (?), it was a small and humble project. But the fact that I squeezed in time after work to build a small project in collaboration with great people made me feel really good — which is why I'm writing a blog post after such a long time.
There are always things to be regretful about, of course.Since it was a side project, maybe I wrote the code too disposably. I wish I had written test code when using Spring-AI, set up Slack alerts so I could fix issues quickly without relying on reports from the client developers, or used JWT-based auth instead of the simplest authentication method I chose for quick implementation — all sorts of thoughts come to mind.
I also realized that the real challenges on the server side truly begin when you're actually in a production environment. Any developer can build APIs quickly, but making those APIs scalable, secure, quickly detectable, and operationally maintainable is an even more critical factor — and this experience really drove that point home. Surprisingly, doing this side project also made me appreciate the various operational skills we use internally at the company even more.
Anyway, that's the end of my rambling! If anyone happens to be reading this, the People's Choice Award voting is currently underway, so I'd really appreciate your vote~! 🙇♀️
사실 공식문서에 너무 잘되어있다. java로 Client, Server 전부 작성해보았다. 결국은 위에서 thrift gen으로 생성한 java 파일안의 클래스와 메서드들을 사용하는게 포인트이며, Thrift 통신을 하기위한 기본적인 구현체인 TSocket, Ttransport 등등은 아래와 같이 thrift 라이브러리를 사용하면 받을 수 있다.
intellij 로 실행할 때 thrift 폴더도 sourceDirectory로 인지하고 해당 폴더 안에 있는 자바 코드를 사용하기 위해 build.gradle에 sourceSets 를 설정해주었다. 또한 intellij 상에서 해당 폴더를 실제 sources로 인식할 수 있게 project structure(command + ;)에서 modules 안에 source로 잘 들어갔는지도 확인해준다.
3-1. Client 코드 작성
thrift gen으로 생성된 파일들의 실제 내용을 보면 알겠지만 RequestWithFlag, CommonRespones와 같은 파일은 요청 응답을 위해 정의한 구조체의 클래스만 들어있다. 즉 app.thrift에서 struct로 정의한 객체들의 파일이다. 실제로 서버로 호출을 하기위한 주된 역할을 하는 java파일은 PostService이며, Client와 Server 각각의 구현체 작성을 위한 코드는 전부 여기있다.
가이드에 따라 Client 코드를 짜고, 내 나름대로 리팩토링을 한다.
package com.jyami.sample.client
import com.jyami.java.thrift.service.CommonResponse
import com.jyami.java.thrift.service.PostService
import com.jyami.java.thrift.service.RequestWithFlag
import org.apache.thrift.protocol.TBinaryProtocol
import org.apache.thrift.transport.TSocket
import org.apache.thrift.transport.TTransport
import java.nio.ByteBuffer
fun main() {
val sampleByte = ByteBuffer.wrap("hello".toByteArray())
connectWithServer { transport ->
val client = makeClient(transport)
client.ping()
val readResponse: CommonResponse = client.read(RequestWithFlag(sampleByte, false))
println("read response $readResponse")
val saveResponse: CommonResponse = client.save(sampleByte)
println("save response $saveResponse")
val removeResponse: CommonResponse = client.remove(sampleByte)
println("remove response $removeResponse")
}
}
fun connectWithServer(process: (transport: TTransport) -> Unit) {
val transport = TSocket("localhost", 9090)
transport.open()
process.invoke(transport)
transport.close()
}
fun makeClient(transport: TTransport): PostService.Client = PostService.Client(TBinaryProtocol(transport))
build.gradle에 넣어준 thrift 라이브러리에 들어있는 것들 TBinaryProtocol, TSocket, TTransport 와 같은 객체들은 전부 thrift를 이용한 socket통신을 하기위해 apache에서 제공하는 추상화된 코드들이다. 해당 객체들을 사용하여 서버와 연결지을 커넥션을 생성하고, thrift.gen으로 만들어진 java 파일들 CommonResponse, PostService, RequestWithFlag를 사용하면 쉽게 클라이언트 코드를 작성할 수 있다.
connectWithServer(), makeClient() 메서드들 각각을 각각 thrift에서 실제 socket 커넥션을 맺는 역할, 호출을 위한 client 객체를 만드는 역할로 각각 코드를 작성해주었다.
connectWithServer로 서버와 connection을 맺고, 해당 서버에 요청을 보낼 내용들은 makeClient로 생성된 PostService.Client객체에 정의된 메서드들을 사용한다. 해당 메서드들은 app.thrift에서 정의한 service들의 메서드임을 알 수 있고, 서버에서 해당 service들에 대한 비즈니스 로직을 채워서 client에 응답을 주면 client는 해당하는 응답에 따라 클라이언트 자체 뷰를 그리기도 하고 print를 하기도하는 등 클라이언트의 요구사항을 채워준다.
3-2. Server 코드 작성
package com.jyami.sample.server
import com.jyami.java.thrift.service.PostService
import org.apache.thrift.server.TServer.Args
import org.apache.thrift.server.TSimpleServer
import org.apache.thrift.transport.TServerSocket
fun main(){
val serverTransport = TServerSocket(9090)
val postServiceImpl = PostServiceImpl()
val server = TSimpleServer(Args(serverTransport).processor(PostService.Processor(postServiceImpl)))
println("Starting the simple server")
server.serve()
}
서버 코드도 클라이언트와 마찬가지로 thrift 라이브러리를 사용하여 ServerSocket을 열어준다. TServerSocket, TSimpleServer(http2와 같은 secure 연결이 되어있지 않은 서버) 를 활용하여 thrift 통신을 하는 서버를 구동시킨다.
이때 해당 서버에 요청이 들어오면 어떤 처리를 할 것 인지를 지정하는 것을 .processor() 메서드로 지정하는데. 이때 처리할 Processor 구현체는 아까 app.thrift에서 생성한 PostService안에 생성이 되어있다.
package com.jyami.sample.server
import com.jyami.java.thrift.service.CommonResponse
import com.jyami.java.thrift.service.PostService
import com.jyami.java.thrift.service.RequestWithFlag
import java.nio.ByteBuffer
class PostServiceImpl : PostService.Iface{
override fun ping() {
println("ping")
}
override fun read(request: RequestWithFlag): CommonResponse {
println("server : read request")
return CommonResponse()
}
override fun save(bsonData: ByteBuffer?): CommonResponse {
println("server : save request")
return CommonResponse()
}
override fun remove(bsonData: ByteBuffer?): CommonResponse {
println("server : remove request")
return CommonResponse()
}
}
실제 해당 서버가 어떤 요청응답을 받는지에 대한 인터페이스는 PostService.Iface 를 이용하면 되기 때문에, 실제 서버에 작성한 프로토콜 명세에 대한 요청을 어떻게 처리할지만 정해주면 된다. PostService.Iface를 구현한 구현체에서 각각의 프로토콜에 대한 비즈니스 로직을 길게 넣어주고 thrift파일에 정의한 프로토콜 명세에 맞게 요청값 응답값을 잘 넣어준다. PostService.Iface의 구현체 즉, 각 프로토콜의 동작이 정의된 비즈니스 로직을 담은 PostServiceImpl을 processor() 메서드 안에 넣어주면, 해당 thrift 서버의 동작을 정의할 수 있는 것이다.
3-3. 실행
위 코드대로 실제로 서버를 구동시키고 클라이언트가 2개 있다는 가정하에 Client 코드를 2번 가동시키면
서버 로그
클라이언트로부터 ping, read, save, remove, ping, read, save, remove 요청을 받아 처리하였다.
클라이언트 로그
서버에 read, save, remove 요청을 보내고 해당하는 응답을 받아 해당 응답을 직접 출력하였다.
3-4. 추가 잡담 - 코드 의도
thrift.app 파일에 int, long, string과 같은 다양한 타입을 정의할 수 있지만, struct에 굳이 binary를 사용한 이유는 thrift로 생성된 객체를 직접 바로 사용하고 싶지 않아서이다.
만약 thrift로 생성된 요청 응답 객체를 직접 사용한다면, 요구사항에 따라 request에 param이 하나가 추가가 되야할 경우 그때마다 thrift.app 파일을 변경하고 그에따라 thrift gen을 이용해서 java 파일을 생성하고 생성된 java 파일에서 변경된 클래스명이나 파라이터 명에 따라 main 코드를 고쳐야한다.
그러나 내가 원하는 요청응답 객체가 있을 때 (Post(title:String, username: String)) 위 객체를 jackson을 이용하여 byinary로 파싱하여 담으면 Post 객체 자체에 대한 요구사항을 훨씬 유연하게 처리할 수 있으면서, 가장 바깥에서 통신하는 thrift 객체는 body가 binary이기 때문에 거의 변화가 없어 위에서 말한 thrift 파일 변경 > thrift gen으로 파일생성 > 이에따른 main 코드 변경이 잦지 않게 되었기 때문에 위와 같은 코드 예시를 선택하였다.
샘플코드라서 오히려 간단해서 구분이 안갈 수 있지만,해당 샘플 코드를 기반으로 나의 의도를 담아 비즈니스로직을 구현한 예시 소스코드가 보고싶다면 아래 링크에 넣어놨다. thrift 뽀개기 끝 ~_~
When it comes to server communication, HTTP is usually the first thing that comes to mind. However, due to the need for something lighter and better cross-language compatibility, and partly because Facebook created it and it gained a lot of popularity, Thrift is also used for server-to-server communication.
Write a Thrift file (IDL). Based on what's written in this file, the request and response formats for Thrift communication on that server will be defined. For IDL syntax and examples, the official documentation's examples are probably the best resource.
Services are defined using the types described above. It's similar to defining an interface. Once a defined service is compiled with the Thrift compiler, Thrift generates both client and server code that can handle requests and responses according to the defined service.
Namespaces
This specifies which language the compiled Thrift IDL should be exported to. The documentation lists all the supported export languages. Since Thrift can generate code for a wide variety of languages, it seems to be particularly advantageous when used for communication between servers written in different languages.
As an example, I wrote a Thrift IDL file like below.
Honestly, the official documentation is really well done. I wrote both Client and Server in Java. The key point is using the classes and methods inside the Java files generated by thrift gen, and the basic implementations for Thrift communication like TSocket, TTransport, etc. can be obtained by using the Thrift library as shown below.
For convenience, I placed the client and server in the same directory.
But the key takeaway is that the various classes and methods — the implementations generated from app.thrift inside the thrift folder —
can be directly used in the actual client or server main code where the business logic resides, enabling Thrift communication.
In an IntelliJ Gradle project setup, I configured several settings so that the code between the main folder and the thrift folder can import and use each other, and also so that IntelliJ can index and recognize them properly in the development environment. I checked in Project Structure (Command + ;) under Modules to make sure the thrift folder was properly registered as a source.
I configured sourceSets in build.gradle so that IntelliJ recognizes the thrift folder as a sourceDirectory and can use the Java code inside it when running. I also verified in Project Structure (Command + ;) under Modules that the folder was properly registered as a source.
3-1. Writing the Client Code
If you look at the actual contents of the files generated by thrift gen, you'll see that files like RequestWithFlag and CommonResponse only contain the struct classes defined for requests and responses. In other words, they are the files for the objects defined as structs in app.thrift. The main Java file responsible for making actual server calls is PostService, and all the code needed to write both Client and Server implementations is in there.
I wrote the Client code following the guide, and then refactored it in my own way.
package com.jyami.sample.client
import com.jyami.java.thrift.service.CommonResponse
import com.jyami.java.thrift.service.PostService
import com.jyami.java.thrift.service.RequestWithFlag
import org.apache.thrift.protocol.TBinaryProtocol
import org.apache.thrift.transport.TSocket
import org.apache.thrift.transport.TTransport
import java.nio.ByteBuffer
fun main() {
val sampleByte = ByteBuffer.wrap("hello".toByteArray())
connectWithServer { transport ->
val client = makeClient(transport)
client.ping()
val readResponse: CommonResponse = client.read(RequestWithFlag(sampleByte, false))
println("read response $readResponse")
val saveResponse: CommonResponse = client.save(sampleByte)
println("save response $saveResponse")
val removeResponse: CommonResponse = client.remove(sampleByte)
println("remove response $removeResponse")
}
}
fun connectWithServer(process: (transport: TTransport) -> Unit) {
val transport = TSocket("localhost", 9090)
transport.open()
process.invoke(transport)
transport.close()
}
fun makeClient(transport: TTransport): PostService.Client = PostService.Client(TBinaryProtocol(transport))
Objects like TBinaryProtocol, TSocket, and TTransport that come from the Thrift library added in build.gradle are all abstracted code provided by Apache for socket communication using Thrift. You create a connection to the server using these objects, and then use the Java files generated by thrift gen — CommonResponse, PostService, RequestWithFlag — to easily write client code.
I wrote the connectWithServer() and makeClient() methods to handle establishing the actual socket connection with Thrift and creating the client object for making calls, respectively.
connectWithServer establishes the connection with the server, and the actual requests sent to the server use the methods defined on the PostService.Client object created by makeClient. You can see that these methods correspond to the service methods defined in app.thrift. When the server fills in the business logic for those services and sends responses back to the client, the client can then render its own views, print output, or fulfill whatever client-side requirements it has.
3-2. Writing the Server Code
package com.jyami.sample.server
import com.jyami.java.thrift.service.PostService
import org.apache.thrift.server.TServer.Args
import org.apache.thrift.server.TSimpleServer
import org.apache.thrift.transport.TServerSocket
fun main(){
val serverTransport = TServerSocket(9090)
val postServiceImpl = PostServiceImpl()
val server = TSimpleServer(Args(serverTransport).processor(PostService.Processor(postServiceImpl)))
println("Starting the simple server")
server.serve()
}
Just like the client, the server code also uses the Thrift library to open a ServerSocket. It uses TServerSocket and TSimpleServer (a server without secure connections like HTTP/2) to start a server that communicates via Thrift.
To specify what processing should happen when a request comes into the server, you use the .processor() method. The Processor implementation used here is already generated inside PostService, which was created from app.thrift.
package com.jyami.sample.server
import com.jyami.java.thrift.service.CommonResponse
import com.jyami.java.thrift.service.PostService
import com.jyami.java.thrift.service.RequestWithFlag
import java.nio.ByteBuffer
class PostServiceImpl : PostService.Iface{
override fun ping() {
println("ping")
}
override fun read(request: RequestWithFlag): CommonResponse {
println("server : read request")
return CommonResponse()
}
override fun save(bsonData: ByteBuffer?): CommonResponse {
println("server : save request")
return CommonResponse()
}
override fun remove(bsonData: ByteBuffer?): CommonResponse {
println("server : remove request")
return CommonResponse()
}
}
Since the interface for what requests and responses the server handles can be obtained through PostService.Iface, all you need to do is define how to process the requests for the protocol specs written on the server. In the implementation of PostService.Iface, you add the business logic for each protocol, and make sure the request and response values match the protocol specs defined in the Thrift file. The implementation of PostService.Iface — that is, the business logic where each protocol's behavior is defined — PostServiceImpl, is passed into the processor() method, which defines the behavior of the Thrift server.
3-3. Running It
Following the code above, after actually starting the server and running the Client code twice (assuming there are 2 clients):
Server Log
It received and processed ping, read, save, remove, ping, read, save, remove requests from the clients.
Client Log
It sent read, save, and remove requests to the server, received the corresponding responses, and printed them out.
3-4. Extra Thoughts - Code Intent
While you can define various types like int, long, string in the thrift.app file, the reason I deliberately used binary in the struct is that I didn't want to directly use the objects generated by Thrift.
If you directly use the request/response objects generated by Thrift, every time a new param needs to be added to a request due to changing requirements, you'd have to modify the thrift.app file, regenerate the Java files with thrift gen, and then update the main code to reflect any changed class names or parameter names.
However, when I have my own desired request/response object (e.g., Post(title:String, username: String)), I can parse it into binary using Jackson and pass it along. This way, I can handle changes to the Post object itself much more flexibly, and since the outermost Thrift object's body is binary, it rarely changes. This means the cycle of modifying the Thrift file → regenerating files with thrift gen → updating main code accordingly happens much less frequently. That's why I chose this code approach.
Since it's sample code, it might actually be too simple to see the distinction clearly,but if you'd like to see the source code where I implemented business logic with my intent based on this sample code, I've put it at the link below. And that's a wrap on cracking Thrift! ~_~
한게 없는데 올려도 될까 회고... 1월 내내 생각 날 때마다 정리하고있는데 하핫 미루고 미루다보니 2월이네..?시간 너무 빨리간다. 회사 다니고 나서부터 3년이 1년처럼 흐르는 느낌이랄까
22년은 사실 개발자로써의 성장보단 운동으로 건강찾다가 재미를 붙여버린 한해였어서 개발 얘기 거의 없는 일기장 회고이다. 자자 시작해보자!!
개발자 쟈미
올해는 외부 스터디나 서브프로젝트 없이 회사 생활에만 집중했었다. 아무래도 그만큼 흥미로운 일을 하고있어서 회사 코드와 구조 그리고 일에 애정이 생기기 때문이 아닌가 싶다.
카카오
지금 부서인 카카오 톡메시징파트에서 일을 하다보면, 이제 3년을 향해가고 있음에도 몰랐던 도메인지식이 나온다. 카카오톡 채팅이라는 매우 큰 서비스와 기능이 많은 서비스를 운영 개발하고있어서 그런거겠지. 도메인적으로 모를때도 스스로 놀라면서 환기가 되기도하고, 사실 기술스택도 다양하고 장애양상이나 그 문제를 해결하는 양상도 다양하여 매울점이 굉장히 많은 조직에 속해있다고 자부심을 느낌다.
22년도에 회사일을 하면서 아무래도 기억에 남는 것들이 몇 개가 있다.
1. 회사 유튜브 출연
작년에는 회사 블로그에 내 글을 썼던걸 회고에 적었었는데, 올해는 유튜브 컨텐츠에 출연을 했다. 개발자로써 훌륭해서라기보단 우리 파트에서 가장 외향적이고, 이런 컨텐츠를 찍으면 내 회사 생활이 재밌을 것 같다고 생각해서 자원했다.
예능 컨텐츠 하나, 인터뷰 컨텐츠 하나해서 두개를 찍었는데 아무래도 기억에 남는건 팀채팅 인터뷰 컨텐츠이다. 파트내에서 팀채팅 서버도 관리하고 있고 팀채팅에 대한 부분도 가끔 유지보수를 하고있는데, 이 좋은 서비스를 많이들 모르는 것 같아 아쉬웠다. 그래서 이전에 내 유튜브에도 올린 팀채팅 활용법에 대한 내용을 영상에 담았다.
그리고 겸사겸사 톡 메시징파트의 롤을 설명하는 내용도 인터뷰에 남겼는데, 덕분에 이 짤을 생성하였지 후후
2. 카카오 해커톤
대학생때 취준을 할 때부터 IT 기업에 가면 임직원 해커톤이 있다는 얘기를 듣고 한번은 꼭 해보고 싶다고 생각했다. 그동안은 코로나로 안열렸었는데, 22년부터 조금 완화가 되고 슬슬 개발자 관련 행사들이 많이 나왔었다. 그래서 참가한 카카오 해커톤 22K 꽤나 재밌었다. 해커톤 영상에도 내가 나온다ㅋㅋ https://youtu.be/j-nXQwSY98o?t=560
우리 팀 빌딩은 모두 카카오톡을 개발하는 크루들이었고, 톡디자인 케이, 톡 안드로이드 피터와 이안, 톡 메시징인 나 이렇게 넷이서 참가하였다. 사내 코드를 써도 되기 때문에 카카오톡 오픈채팅을 변경한 서비스를 만들었고, 지난 코로나 시대에 오픈채팅 팬미팅, 오픈채팅 콘서트가 종종 이루어진 것을 봤었어서. 팬미팅에 사용할 수 있도록 팬덤색이나 팬덤 로고들을 좀더 커스텀해서 팬들과 스타가 소통할 수 있는 채팅기능을 개발하였다. 시연영상은 내 유튜브에 비공개로 저장해뒀다ㅎㅎ 나중에 보면 매우 추억일 것 같은 느낌!
3. 제주도 출장
22년에 제주도만 3번을 다녀왔었는데, 그중 2번이 회사관련 출장이었다. 한번은 태경이 수영이랑 같이 제주도 여행을 다녀왔었고, 한번은 if-kakao 컨퍼런스 준비단 워크샵, 그리고 아래 vlog찍을 때 갔던건 포팅과제 집중근무를 위한 제주 출장이었다. 일도 하면서 좋은경치 맛있는 음식 잔뜩먹으면서 제주도 혼자 여행을 다녀오다보니 당시에 리프레쉬도 되었고, 22년도 기억에 남는 일중 하나였다. 본사가 제주에 있는 회사에 다니니 워크샵 제주 힐링그자체!!
vlog에서도 언급을 했었지만 당시에 만난 케빈과 조엘이 엄청 인상적이었다. 두분은 같은 학교 동문, 그리고 당시에 두분 다 유관 부서로 한달 제주도 워케이션을 하신다고해서 한번 만남을 가졌었다. 생활패턴과 개발철학이 비슷해서 마음이 맞는친구와 한달동안 알차게 여행 겸 근무를 할 수 있는 사람이 있다는게 정말 부러웠다. 나두 23년에 조엘이랑 떠나는 스위스 여행 매우 기대중 ㅎㅅㅎ
올해는 리팩토링 업무, 그리고 기존 레거시 포팅작업이 나의 주된 과제였었는데, 그 와중에도 유저가 직접 사용하는 기능 개발에도 참여하곤했었다. 너무 내부과제에만 치중하다보니 스스로 번아웃이 오고 개발로 좀 재미를 찾고 싶었기 때문에 실제 유저가 사용할 수 있는 기능 개발을 하고싶다고 생각을 했었다.
그렇게 했던 과제가 추모 프로필이었는데 하필이면 12월 가장 바쁠 시기에 내가 여행을 일주일 다녀오는 바람에 같이 일을 했던 빈스에게 매우 죄송했다. 그래도 전후로 나름 열심히 팔로우 했던 프로젝트! 사실 서버 공수가 많지는 않았지만 23년 1월에 오픈되고 유저들의 반응이 너무 좋아서 뿌듯했다. 덕분에 사용자와 밀접한 서비스를 만들게되면 또 다른 멋진 기능을 개발, 혹은 기존 기능들을 개선 할 수 있도록 힘을 낼 수 있는 계기가 되어 개발자로 자부심있게 살 수 있게 되는 것 같다.
판교 장애 대응은 앞으로 개발자로 계속 산다고 해도 이정도 규모의 장애를 대응해볼 일이 있을까 싶을정도로 기억에서 안잊혀질 것 같다. 토요일 3시부터 시작해서 일요일 오전 7시까지 쉼없이 대응하고 2시간 자서 다시 일어난다음 일요일 9시부터 00시까지 일하고.. 그러고 월요일도 9시 출근해서 00시까지 일하고.. 어떻게든 빠르게 복구해야한다는 생각밖에 안들었던 당시였다. 내가 자는시간만큼 내 주변인들이 서비스를 사용하지 못한다고 생각하니, 진짜 아드레날린이 너무 몰아쳐서 심장이 계속 두근거리고 잠을 못자는 상황이었다. 그래도 물리적장애를 소프트웨어적으로 빠르게 해결하려고 대응책을 세우고 실제로 하나하나 대응되는 대로 서비스가 살아나는 것을 보면서 재밌기도했고 개발자로써 희열을 엄청 느꼈던 사건이었다.
월드컵 트래픽으로 신년 트래픽으로 혹시나 서버에 이상이 있을까 뒤에서 모니터링을 했었다. 우리 파트에 있으면 사용자의 패턴에 따라 내 서비스의 트래픽이 오르고 내리는 것을 볼 때 정말 신기함을 느낀다. 실제 대한민국 대부분 국민들의 서비스 사용성을 직접 데이터로 볼 수 있다는 점에서 항상 많은 인사이트를 얻고 그에 따른 대응 로직을 준비하고 대비하면서 많은 배움을 얻는다. 첫 직장 첫 부서가 대규모 트래픽을 감당하기 위해 많은 것을 고려해야하는 파트라는 점에 항상 감사함을 느낀다.
개발자 외부 활동
1. 블로그
22년 방문자수
월간 방문수 약 13000명대를 유지하고있다. 사실 글도 잘 안쓰는데.. 이전에 스프링 기본기에 대해 정리해뒀던 문서나 회고 글들이 인기가 많아서 꾸준히 유입이 있다. 23년에는 블로그에 글을 많이 쓸랑가
구독자가 3400명이 되었다. 22년에는 광고영상 1개, 카톡팁 영상 1개, 제주 vlog 영상 1개.. 하핫 올리고 싶을 때 취미로 하는 유튜브라서그런지 꾸준히 하지 못해서 구독자가 확실히 크게 우상향하지는 않는다.
그래도 가끔 회사에 신입사원분들이 들어오실 때 블로그나 유튜브와 같이 열심히 살던 과거의 영광들을 봐주시고 감사하게도 좋게봐주셔서 알아봐주시는 분들이 계시다. 그런만큼 열심히 살아야 하는데..ㅠㅠ 22년에는 아무래도 개발자로서의 성장보다 다른데 좀더 집중해서 살다보니 블로그도 유튜브도 업로드가 많이 이루어지지 않았었다.
3. 세미나
외부 컨퍼런스에 잘 나가는 편은 아니지만 지속적으로 대학교 선후배들과의 네트워크는 하려고 학교 행사에는 많이 참여하려고 하는 편이다. 22년에는 총 3번의 세미나를 진행했었는데, 아무래도 전부 취준을 앞둔 대학생 대상이다보니 커리어에 대한 이야기를 많이 했다.
1월 GDSC EWHA 선배초청 세미나 : 서버개발자가 아키텍처 확장해 나가는 플로우
11월 이화여대 컴퓨터공학과 클라우드 데이 : 개발자는 어떻게 공부해야할까
11월 GDSC EWHA 홈커밍 데이 : 서버개발자에게 궁금한 점 QnA
발표를 준비하면서 아무래도 내가 개발을 어떻게 공부를 했었고, 앞으로는 어떻게 공부를 해야겠다는 생각을 정리할 수 있었다. 그래서 다들기술 발표를 하고 멘토링을 하라는 이유가 스스로도 되짚어볼 수 있게되기 때문인가보다. 개발자는 어떻게 공부해야할까? 라는 점에 대해서 아키텍처가 점점 확장되면서 요구사항에 따라 그때그때 공부를 확장해가면서 해야한다는 이야기를 했었다. 면접에서 cs를 본다고해서 그것을 주먹구구로 외우는 방식보다는 직접 서비스나 프로젝트를 하면서 그에 따른 지식을 익혔던 것이 기억에 많이 남는다는 것이 주된 주제였다. 다행히도 많은 후배분들이 질문도 많이 해주시고 연락도 많이 해주셔서 뿌듯함과 그들의 열정을 느끼는 일정이었던게 기억에 남는다.
GDSC에서 요청이 와서 서면 인터뷰를 했었다. 사실 취준기에 대해서 이 블로그를 통해 유명해지긴 했으나,, 어느새 직장을 다닌지 만으로 3년차이기에 너무 라떼는 얘기가 아닐지 걱정이된다. 운동을 하고있는 지금 입장에서는 과거에 운동도안하고 무작정 밤샘을 하던 나의 모습이 좋지 않다는 걸 특히나 더 실감하고 있어서 더 그렇다.
5. 스터디?
주된 관심사가 아무래도 운동이었어서 개발 공부를 해야한다는 생각은 한켠에만 있고 그러다보니 옛날만큼 퇴근 후 공부를 많이 하진 않았다. 3월부터 6월까지는 자바봄이랑 effective kotlin 책으로 코틀린 스터디를 했었다.
effective java만큼 인사이트를 주지 않을까 하여 사실 많이 기대했던 책인데 아직은 코틀린이 자바만큼 안티패턴이나, 주의해야할 점 등 사례가 많이 쌓이진 않았어서 effective java만큼 충격적으로 다가오진 않았다. 아직도 내 최고의 명서는 effective java... 오히려 코틀린은 kotlin in action 이 좀더 실용적이고 내용이 알찬게 좀 더 마음에 들었다.
마찬가지로 자바봄이랑 이펙티브 코틀린을 진행할 때 github 코드 정리와 블로그 정리를 동시에 했었는데 관련 링크는 아래에 있다
직장을 다니면서 내가 원하는 깊이로 마음맞는 사람들과 스터디를 하는게 쉽지 않다는걸 깨닫게되었다. 대학교에 다닐때 자바봄을 만난건 매우 행운이었구나 생각이 들었다. 고로 앞으로 공부를 한다면 스스로 흥미를 찾아서 꾸준히 해야할텐데 쉽지않다ㅠ 사회에는 재밌는게 너무 많다! 앞으로의 공부방법에 대해서는 항상 고민으로 두고 찾아가야 할 것 같다.
운동인 쟈미
사실 본론은 여기일지도 위에는 그래도 양심상 제목이 devlog니까 개발자를 위로 올렸는데, 22년의 진짜 본모습은 운동인이었다ㅋㅋㅋ 21년에 시작한 운동이 생각보다 재밌었고, 22년 2월부터 클라이밍에 빠지게 되면서 꾸준히 운동을하고있는데, 운동하나를 시작하니 다른 운동도 곧잘해서 이것저것 많이 시도하고 도전했었던 한해였다.
1. 클라이밍
2월부터 꾸준히 하고있는 운동이다. 사실 진짜 운동하는 느낌은 웨이트가 그렇고, 클라이밍은 운동이지만 승부욕이 많이 생겨서 게임하는 느낌이긴 하다. 꾸준히 했더니 처음보다 실력이 많이늘었고, 클라이밍으로 새로운 사람들을 많이 만나면서 22년을 덕분에 즐겁게 보낼 수 있었다.
22년 클라이밍 달력
위에 달력 보면 진짜 많이도 했다 싶다..ㅋㅋㅋㅋ 암장리스트도 싹 정리하니 많이도 다녔다..ㅎㅎ
클라이밍안에도 많은 종류가 있는데 이것저것 해보기를 좋아해서 그런지 실내볼더링 인공암벽리드 자연볼더링 자연리드 가릴 것 없이 많이 했다. 클라이밍을위해 먼 지역에 여행을 가기도 하면서 참 많이 놀러다녔다. 클라이밍이 너무 해보고싶어서 언더독 클라임에 무작정 일일강습을 신청했고, 진짜 재밌었다. 그래서 이후에 혼자 암장을 가서 사람들이랑 친해지기도하고, 그렇게 친해진 사람들의 친구들을 소개받으면서 같이 클라이밍을 하고 다니면서 다양한 곳을 다니게 되었다.
3월에서 4월까지는 모란 클라임어스에서 기초반 강습을 들었었고, 그 이후에 한 5월쯤인가 부터 지금까지 계속 더클라임 회원권을 연장해서 실내 볼더링을 하고있다. 처음에 더클라임 초록도 쩔쩔맸었는데, 어느새 갈 때마다 빨강을 한두개씩 깨게 되고 22년 마지막에 보라색도 하나 했다!! 9월쯤 헬스랑 함께 클라이밍을 했을 때까지 실력이 엄청 빠르게 늘어서 매번 재밌었는데, 사실 22년 끝물에 연말이라고 술을 너무 많이 먹었더니 근손실이 왔는지 조금 정체했다..ㅎㅎ 23년에는 헬스도 클라이밍도 꾸준히 하면서 좀 더 잘해지고싶다!
무엇이든 신기한 클린이는 상반기에는 서울 근처 암장투어를 정말 많이 다녔었고, 결국엔 클라이밍을 위한 여행도 많이 가게 되었다. 부산, 속초, 대전, 제주, 양양, 진안 심지어 태국까지 어느 여행지를 가게되도 클라이밍을 연상하는 클친자가 되어가는 중이다. 하반기에는 더클라임 회원권을 끊게되면서 이곳저곳 원정을 안가게 되었고, 실내가 아닌 실외에 관심을 갖게되었다.
9월에 가을이 되면서 날씨가 좋아지고,, 날씨가 좋아지니 실내보다는 밖을 나가고 싶어서 결국 리드를 시작하게 되었다. 근처 주민인 소나언니한테 리드를 배워서 결국 리드 클라이밍을 꾸준히 하고있는 돌무리 크루에 들어오게 되었다. 가을에 이쁜 하늘을 보면서 클라이밍을 하고싶어서 배운 리드를 인공암벽에서 시작해서 결국 실제 자연바위에서도 리드를 하게 되었고, 태국 끄라비까지 가게 되었다. 끄라비 자연리드는 아무래도 22년에 가장 기억에 남는 이벤트였었고, 같이간 우리 돌무리 언니오빠들이랑 하나도 안싸우고 서로서로 챙기면서 8박9일 클라이밍 겸 태국여행을 무사히 다녀올 수 있어서 감사했다.
외에도 더클라임에서 진행하는 걸스온탑, 클라임어스에서 진행하는 볼더링 파티도 참가해보면서 한정된 시간안에 많은 문제 혹은 고득점 문제를 풀어야하는 긴장감도 경험해볼 수 있었다. 사실 이런 이벤트를 할 때마다 내가 좀더 강했다면하고 그레이드를 많이 낮춰서 나가게 되는데, 그래도 1년안에 이정도면 꽤 잘하는거니까!!! 23년에도 다양한 이벤트를 많이 나가보는걸로 하자
재밌겠다는 생각 하나로 시작한 취미로 다양한 직군의 사람들을 만날수 있게되었고, 취미를 위해 여행을 떠나는 삶을 내가 살고있을거라고는 생각도 못했었다. 사실올 한해클라이밍과 운동에푹 빠져있어서 덕분에 퇴근하고 개발공부보단 운동을 하러가는 일상이 반복되었지만 , 그만큼 많이 건강해진 패턴을 가지게되어서 다행이라고 생각한다. 22년에는 운동에만 미쳐있었다면 23년에는 그래도 현생도 조금은 챙기면서 운동을 하고 싶다.
볼더링 (실내 28 + 자연 2)
언더독 클라이밍 (수원)
더클라임 (양재 + 강남 + 신림 + 서울대 + 마곡 + 홍대 + 연남 + 일산)
클라임어스 (모란)
피커스클라이밍 (종로)
서울숲클라이밍 (서울숲)
클라이밍파크 (종로 + 신논현 + 한티)
에픽클라임 (영통)
닷클라이밍 (송파)
볼더메이트 (기흥)
락트리 (분당)
비블럭 클라이밍 (언주 + 송도)
알레 클라이밍 (혜화)
손상원 클라이밍짐 (강남)
원정 : 아임낫볼더 (속초)
원정 : 웨이브락 (광안리, 서면)
원정 : 픽스볼더 (제주)
원정 : 베이스캠프 (대전)
자연바위 : 양양 죽도암
자연바위 : 진안 운일암반일암
리드 (인공암벽 4 + 자연 2)
판교 공원
뚝섬 한강 공원
영등포 스포츠 클라이밍 경기장
광교 스포츠 클라이밍장
자연리드 : 조비산
자연리드 : 끄라비 (태국)
이벤트
피커스 볼빼페 (볼더링 빼고 페스티벌)
더클라임 걸스온탑
더클라임 강남점 오픈페스티벌
모란 볼더링 파티
2. 헬스
그래서 3대몇? 스쿼트가 잘 기억이 안나는데 S : 55kg / B : 32.5kg / D : 75KG = 3대 162.5kg 이다. 요즘엔 헬스를 잘 안해서 3대 운동을 잘해서 아마 더 많이 내려갔을 텐데ㅠㅠ 1월부터 10월까지 꾸준히 PT를 했을때 기록이었다. PT를 22년에 꽤 많이 받았더니 돈도 많이 들고, 사실 기구 사용법이나 자극도 왠만해서는 혼자도 할 수 있는 정도가 되어 11월부터는 PT없이 혼자서 하고있다. PT거의 마지막 즈음에는 내가 고립운동을 재미없어하는걸 쌤이 느끼셨는지 크로스핏이나 역도 동작도 시켜보고ㅋㅋ 또 곧잘하니까 선생님도 재밌어하고 했었다ㅋㅋ 운동에 한번 흥미를 느끼니 "고립운동"이라서 하는게 아니라 그냥 운동이면 무엇이든지 일단 도전해보게 되었다.
22년 1월 인바디와 22년 9월 인바디 차이이다. 12월에 했어야했는데 생각을 못했다ㅠㅠ 식단없이 평소대로 식습관을 하면서 오로지 운동만으로만 이루어낸 결과이다. 목표로 운동을 한것은 아니었지만 몸 라인이 달라지고 데이터로도 나아지는 것을 보면서 보람을 느꼈고, 몸도 이전보다 많이 건강해졌다는걸 느끼고있다. 생활속에서도 옛날에는 무거운 물건을 옮기는걸 굉장히 부담스러워했는데, 어느순간 혼자서도 척척 잘 옮길 수 있게 되서 나름 삶의질도 높아졌다.
지금은 클라이밍을 주운동으로해서 헬스를 많이 하고있지는 않지만, 그래도 클라이밍과 반대되는 근육 발달을 위해 일주일에 한번이라도 헬스장을 가고있긴하다. 외에도 너무 몸이 무거울 때 유산소를 가볍게 하면 기분도 나아지고 좀 가벼워지는 기분이 든다. 하지만 앞으로 헬스를 주운동으로 하지는 않을 것 같다. 고로 3대측정도 계속 낮아지겠지.. 적당한 건강유지 정도를 위해 할 예정이다.
3. 일회성 운동 체험
클라이밍과 헬스로 점점 운동에 재미를 붙이다보니 사실 일회성으로도 여러 운동에 도전해보는걸 주저하지 않게되었다. 인생에서 처음 스키장에 가서 스키를 타보기도하고, 프리다이빙 체험을 하려다가 자격증 코스 수업을 듣기도했다 (근데 성격이 급해서 그런가.. 나랑은 잘 안맞아서 그만뒀다). 클라이밍의 다이나믹 무브를 잘하고싶어서 언더커버에 파쿠르 체험을 가서 파쿠르 코치님들이랑 친해지기도했다. 유산소를 진짜 싫어해서 절대 안할줄 알았던 러닝도 생각보다 처음하는 것 치고 기록이 잘나와서 꽤 흥미로웠다. (5km 6분 11초)
코딩에서 하나의 언어를 잘 알면 다른 언어를 배울 때 좀더 수월하게 배우는 것처럼 운동도 비슷한 느낌이 들었다. 어느정도 헬스와 클라이밍으로 상체와 하체 근육이 받쳐주다보니 다른 운동도 처음시작하는 것 치고 곧잘하는 느낌이 들어 빠르게 흥미를 붙일 수 있게 될 것 같다. 다만 그래도 아직은 클라이밍이 너무 재밌다..ㅎㅎ
그래서 23년에는..
글의 분위기에서도 느껴졌겠지만 개발 얘기할 때는 조금은 차분하게 운동얘기할 때는 매우 활기차게 글을 썼다ㅋㅋㅋ. 그런만큼 22년에는 개발자로서의 성장보다는 운동으로 건강돌리기와 재미찾기가 우선인 한 해 였다. 하지만 언제까지 재미만 찾아다닐 순 없겠지ㅠ 그래서 어떻게 하면 개발 공부를 좀 더 재밌게 할 수 있을까 고민중이다. 시니어 개발자분들중에 한분은 본인의 취미를 개발과 접목시키면 결국 관심사라서 공부를 하게 된다고 하셨었다. 그래서 퇴근하고 사이드프로젝트로 내가 쓰고싶은 클라이밍 관련 서비스를 만들어 볼까 생각도 해보고있다. 22년은 근육만 성장했다면, 23년은 근성장, 개발자로서의 성장 둘다 잡는 멋진 한 해를 만들어보자!! 화이팅!
I don't even have much to show for it, but is it okay to post a year-end retrospective... I've been jotting things down whenever they come to mind throughout January, but haha I kept putting it off and now it's February..? Time flies so fast. Ever since I started working, it feels like 3 years go by like 1 year
2022 was honestly a year where I found fun in working out and getting healthy rather than growing as a developer, so this is more of a diary-style retrospective with barely any dev talk. Alright, let's get started!!
Developer Jyami
This year, I focused solely on work life without any external study groups or side projects. I think it's because the work I'm doing is interesting enough that I've grown attached to the company's code, architecture, and the work itself.
Kakao
Working in my current department, the KakaoTalk Messaging Part, even as I'm approaching my 3rd year, I still come across domain knowledge I didn't know about. I guess that's because we're operating and developing KakaoTalk Chat — a massive service with tons of features. When I encounter something I didn't know domain-wise, I surprise myself and it's a nice wake-up call. The tech stack is diverse, the types of incidents and how we resolve them vary widely too, so I feel proud to be part of an organization where there's so much to learn.
There are a few things from work in 2022 that really stick out in my memory.
1. Appearing on the Company YouTube
Last year I wrote about publishing a post on the company blog in my retrospective, and this year I appeared in YouTube content. It wasn't because I'm an outstanding developer — I'm just the most extroverted person on our team, and I volunteered because I thought filming this kind of content would make my work life more fun.
We filmed two videos — one entertainment piece and one interview piece — and the one that stands out most is the Team Chat interview content. Our part manages the Team Chat server and occasionally does maintenance on it, and I always thought it was a shame that not many people knew about this great service. So I included tips on how to use Team Chat, which I had also previously uploaded on my own YouTube channel.
While I was at it, I also explained the role of the Talk Messaging Part in the interview, and thanks to that, I got this meme-worthy screenshot hehe
2. Kakao Hackathon
Ever since my college days when I was job hunting, I'd heard that IT companies have employee hackathons, and I always wanted to try one. They hadn't been held due to COVID, but starting in 2022, restrictions eased up and a lot of developer events started popping up. So I participated in the Kakao Hackathon 22K, and it was pretty fun. I even appear in the hackathon video lol https://youtu.be/j-nXQwSY98o?t=560
Our team was made up entirely of crew members who develop KakaoTalk — Kay from Talk Design, Peter and Ian from Talk Android, and me from Talk Messaging, four of us total. Since we were allowed to use internal code, we built a modified version of KakaoTalk Open Chat. During COVID, I'd seen fan meetings and concerts held through Open Chat, so we developed a chat feature that let fans and stars communicate with more customized fandom colors and logos for fan meetings. I saved the demo video as unlisted on my YouTube hehe — I feel like it'll be a great memory to look back on later!
3. Jeju Island Business Trip
I went to Jeju Island 3 times in 2022, and 2 of those were work-related trips. Once I went on a personal trip with Taekyung and Suyoung, once was a workshop for the if-kakao conference preparation team, and the trip I vlogged about below was a Jeju business trip for focused porting work. Working while enjoying beautiful scenery and eating tons of delicious food, basically a solo trip to Jeju, was so refreshing at the time, and it's one of the most memorable things from 2022. Working at a company with headquarters in Jeju means workshop trips to Jeju are pure healing!!
As I mentioned in the vlog, meeting Kevin and Joel at the time was really impressive. They're alumni from the same school, and both were doing a month-long Jeju workation in a related department, so we met up. Our lifestyles and development philosophies were similar, and I was really envious that they had someone whose vibe matched so well to travel and work with for a whole month. I'm super excited for my Switzerland trip with Joel in '23 too hehe
This year, refactoring work and porting legacy code were my main tasks, but I also got involved in developing user-facing features along the way. Being too focused on internal tasks was burning me out, and I wanted to find some fun in development again, so I thought I'd like to work on features that actual users would use.
The project I ended up working on was the Memorial Profile feature, but unfortunately, I happened to go on a week-long trip during the busiest time in December, so I felt really bad for Vince who was working on it with me. Still, I did my best to follow up before and after! The server workload wasn't that heavy honestly, but when it launched in January '23 and the user response was so positive, I felt really proud. Thanks to that experience, whenever I get to build a service that's close to users, it motivates me to develop more awesome features or improve existing ones, and it makes me feel like I can live with pride as a developer.
5. Pangyo IDC Outage Response / World Cup Response / New Year's Response
Q4 was a whirlwind. With all sorts of incident responses, I ended up working in the early morning hours a lot.
The Pangyo outage response is something I'll never forget — even if I keep working as a developer for the rest of my life, I doubt I'll ever deal with an incident of that scale again. It started at 3 PM Saturday and I worked non-stop until 7 AM Sunday, slept for 2 hours, got back up and worked from 9 AM Sunday until midnight.. Then on Monday, went in at 9 AM and worked until midnight again.. All I could think about at the time was recovering as fast as possible. Knowing that for every moment I was sleeping, people around me couldn't use the service — the adrenaline was pumping so hard my heart wouldn't stop racing and I couldn't sleep. But watching the services come back to life one by one as we devised software solutions for a physical outage was actually exciting, and it was a moment where I felt an incredible thrill as a developer.
For the World Cup traffic and New Year's traffic, I was monitoring from behind the scenes in case anything went wrong with the servers. Being on our team, it's truly fascinating to watch the traffic on our service rise and fall based on user patterns. The fact that we can directly see usage data from most of the Korean population through actual data always gives me a lot of insights, and I learn so much from preparing and implementing response logic accordingly. I'm always grateful that my first job and first team is one that has to consider so many things to handle massive traffic.
External Developer Activities
1. Blog
2022 Visitor Count
I'm maintaining about 13,000 monthly visitors. I honestly don't even write that much.. but the Spring fundamentals posts and retrospective posts I wrote before are popular, so there's a steady stream of visitors. Maybe I'll write more blog posts in '23
I hit 3,400 subscribers. In 2022, I only uploaded 1 sponsored video, 1 KakaoTalk tips video, and 1 Jeju vlog.. haha since it's a hobby YouTube channel I upload whenever I feel like it, so naturally the subscriber count isn't growing dramatically.
Still, sometimes when new employees join the company, they've seen the past glories of me working hard through the blog or YouTube, and thankfully they think positively of it and recognize me. That means I should keep working hard but..ㅠㅠ In 2022, I was more focused on things other than growing as a developer, so I didn't upload much to the blog or YouTube.
3. Seminars
I don't go to external conferences much, but I try to participate in school events to keep networking with university seniors and juniors. In 2022, I gave 3 seminars in total, and since they were all aimed at college students preparing for job hunting, I mostly talked about careers.
January — GDSC EWHA Alumni Seminar: The flow of how a server developer scales architecture
November — Ewha Womans University Computer Science Cloud Day: How should developers study?
November — GDSC EWHA Homecoming Day: Q&A about things you're curious about as a server developer
While preparing the presentations, I was able to organize my thoughts on how I had studied development and how I should study going forward. So I guess that's why everyone says to give tech talks and do mentoring — because it lets you reflect on yourself too. On the topic of "How should developers study?", I talked about how as architecture gradually expands, you should expand your studies on-the-fly based on the requirements at hand. The main point was that rather than rote-memorizing CS concepts just because they come up in interviews, the knowledge you gain from actually building services or projects sticks with you much more. Fortunately, many juniors asked lots of questions and reached out to me afterward, so I remember it as an event where I felt proud and could feel their passion.
GDSC reached out to me, so I did a written interview. I actually became well-known through this blog during my job-hunting days, but now that I've been working for a full 3 years, I worry if my stories are becoming too "back in my day." Especially now that I'm working out, I realize even more how unhealthy it was to just pull all-nighters without exercising back then.
5. Study Groups?
Since my main interest was working out, the thought of studying development was just sitting in the back of my mind, so I didn't study much after work like I used to. From March to June, I did an Effective Kotlin book study with Javabom.
I had high expectations, thinking it would give insights like Effective Java, but Kotlin hasn't accumulated as many anti-patterns or gotchas as Java yet, so it didn't hit me as hard as Effective Java did. My all-time best book is still Effective Java... For Kotlin, I actually preferred Kotlin in Action — it felt more practical and had richer content.
Similarly, when doing Effective Kotlin with Javabom, I organized code on GitHub and wrote blog posts at the same time. The related links are below:
I realized that it's not easy to find like-minded people to study with at the depth I want while working a full-time job. Meeting Javabom in college was truly lucky. So if I'm going to study going forward, I'll need to find my own motivation and keep at it consistently, but that's easier said than done ㅠ There are too many fun things in life! I think figuring out how to study going forward is something I'll need to keep thinking about.
Jyami the Athlete
Honestly, this might be the real main topic. I put the developer stuff up top out of conscience since the title says devlog, but my true identity in 2022 was an athlete lol. The workouts I started in 2021 turned out to be more fun than expected, and after getting hooked on climbing starting February 2022, I've been exercising consistently. Once I started one sport, I naturally picked up others too, so it was a year of trying and challenging myself with all sorts of things.
1. Climbing
This is the sport I've been doing consistently since February. Honestly, weight training feels more like a "real workout," while climbing is technically exercise but it fires up my competitive side so much that it feels more like a game. With consistent practice, my skills improved a lot from the beginning, and I got to meet so many new people through climbing, which made 2022 a really enjoyable year.
2022 climbing calendar
Looking at the calendar above, I really did go a LOT lolol. And when I compiled my gym list, I visited so many places too hehe.
There are actually many different types of climbing, and since I like trying all sorts of things, I did everything without discrimination — indoor bouldering, artificial wall lead climbing, outdoor bouldering, and outdoor lead climbing. I even traveled to faraway places just for climbing and went on tons of trips. I wanted to try climbing so badly that I just signed up for a one-day lesson at Underdog Climb on impulse, and it was seriously fun. After that, I started going to climbing gyms on my own, made friends with people there, got introduced to their friends, and ended up climbing together and visiting all kinds of places.
From March to April, I took beginner classes at Moran Climb Us, and after that, starting around May I think, I've been renewing my membership at The Climb for indoor bouldering ever since. At first I struggled even with The Climb's green problems, but before I knew it, I was clearing one or two red problems each visit, and at the end of 2022, I even completed a purple one!! Until around September when I was combining weight training with climbing, my skills were improving super fast and it was fun every time. But honestly, toward the end of 2022, I drank way too much because of year-end gatherings, and I think I lost some muscle because I hit a plateau.. hehe. In 2023, I want to keep doing both weight training and climbing consistently and get even better!
As a climbing newbie curious about everything, I toured a ton of climbing gyms around Seoul in the first half of the year, and eventually ended up going on lots of climbing trips too. Busan, Sokcho, Daejeon, Jeju, Yangyang, Jinan, and even Thailand — no matter where I traveled, I was becoming that climbing-obsessed person who associates every destination with climbing. In the second half, after getting a membership at The Climb, I stopped going on expeditions to different gyms and became more interested in outdoor climbing rather than indoor.
As autumn arrived in September and the weather got nicer, I wanted to be outside rather than indoors, so I ended up starting lead climbing. I learned lead climbing from Sona unnie, who lives nearby, and eventually joined the Dolmuri crew, who regularly do lead climbing. I wanted to climb while looking at the beautiful autumn skies, so I started with lead climbing on artificial walls and eventually progressed to actual natural rock faces, even traveling all the way to Krabi, Thailand. The outdoor lead climbing in Krabi was definitely the most memorable event of 2022, and I was grateful that all of us Dolmuri crew members got along without a single fight, looked out for each other, and safely completed the 8-night, 9-day climbing and Thailand trip.
On top of that, I participated in Girls On Top hosted by The Climb and the bouldering party hosted by Climb Us, where I got to experience the thrill of solving as many problems or high-scoring problems as possible within a limited time. Honestly, every time I did these events, I wished I were a bit stronger and ended up registering in a lower grade category. But still, this is pretty good for just one year of climbing!!! Let's make sure to participate in lots of events in 2023 too.
What started from a simple thought of "this seems fun" turned into a hobby that let me meet people from all different professions, and I never imagined I'd be living a life where I travel for my hobbies. Honestly,this whole yearI was so deep intoclimbing and exercise that my daily routine after work became going to work out rather than studying development. But I think it's a good thing because I ended up with a much healthier lifestyle. If 2022 was all about being obsessed with exercise, in 2023 I want to exercise while also taking care of real life a bit more.
Bouldering (Indoor 28 + Outdoor 2)
Underdog Climbing (Suwon)
The Climb (Yangjae + Gangnam + Sillim + Seoul National Univ. + Magok + Hongdae + Yeonnam + Ilsan)
Climb Us (Moran)
Peakers Climbing (Jongno)
Seoul Forest Climbing (Seoul Forest)
Climbing Park (Jongno + Sinnonhyeon + Hanti)
Epic Climb (Yeongtong)
Dot Climbing (Songpa)
Boulder Mate (Giheung)
Rock Tree (Bundang)
B-Block Climbing (Eonju + Songdo)
Allez Climbing (Hyehwa)
Son Sangwon Climbing Gym (Gangnam)
Expedition: I'm Not Boulder (Sokcho)
Expedition: Wave Rock (Gwangalli, Seomyeon)
Expedition: Fix Boulder (Jeju)
Expedition: Basecamp (Daejeon)
Natural Rock: Yangyang Jukdo-am
Natural Rock: Jinan Unil-am Banil-am
Lead (Artificial Wall 4 + Natural 2)
Pangyo Park
Ttukseom Hangang Park
Yeongdeungpo Sports Climbing Arena
Gwanggyo Sports Climbing Center
Outdoor Lead: Jobisan
Outdoor Lead: Krabi (Thailand)
Events
Peakers Bouldering Festival
The Climb Girls On Top
The Climb Gangnam Branch Opening Festival
Moran Bouldering Party
2. Weight Training
So what's your big three? I don't remember squat exactly, but S: 55kg / B: 32.5kg / D: 75kg = Big Three total of 162.5kg. I haven't been doing much weight training lately so I'm not great at the big three lifts, and the numbers have probably dropped even more ㅠㅠ These were my records when I was consistently doing PT from January to October. I did quite a lot of PT sessions in 2022 so it cost a lot, and honestly I got to the point where I could handle equipment usage and muscle activation on my own well enough, so starting November I've been working out solo without a trainer. Toward the end of my PT sessions, my trainer must have noticed I found isolation exercises boring, so they had me try CrossFit and weightlifting movements too lol. And since I picked them up quickly, my trainer had fun with it too lol. Once I found interest in exercise, it wasn't about doing "isolation exercises" anymore — I became someone who just wants to try any kind of exercise.
This is the comparison between my InBody results from January 2022 and September 2022. I should have done one in December but I forgot ㅠㅠ These results were achieved purely through exercise alone, without any diet changes — just eating the way I normally do. I didn't set specific body goals, but seeing my body shape change and the data improve gave me a real sense of accomplishment, and I can feel that my body has become much healthier than before. In daily life too, I used to find it really burdensome to move heavy objects, but at some point I became able to move them easily by myself, which actually improved my quality of life.
Right now I'm not doing much weight training since climbing is my main workout, but I still try to hit the gym at least once a week to develop the muscles opposite to the ones used in climbing. Also, when my body feels really heavy, doing some light cardio improves my mood and makes me feel lighter. But I don't think I'll be making weight training my main workout going forward. So my big three numbers will probably keep going down.. I plan to do it just enough to maintain reasonable health.
3. One-off Sport Experiences
As climbing and weight training got me more and more into exercise, I became unafraid to try various sports even if just once. I went to a ski resort for the first time in my life and tried skiing, and I was going to just try freediving but ended up taking a certification course (though I guess I'm too impatient.. it didn't really suit me so I quit). I wanted to get better at dynamic moves in climbing, so I went to Undercover for a parkour experience and ended up becoming friends with the parkour coaches. I also tried running, which I always thought I'd never do because I absolutely hated cardio, but my times were surprisingly good for a first-timer, so it was pretty interesting. (5km in 6 minutes 11 seconds)
Just like how knowing one programming language well makes it easier to learn another, I felt the same applies to sports. Since I had built up a decent foundation of upper and lower body muscles through weight training and climbing, I could pick up other sports pretty quickly for a beginner, which made it easy to get interested fast. But still, climbing is just too fun for now.. hehe.
So in 2023..
You could probably feel it from the tone of this post, but I wrote calmly when talking about development and super energetically when talking about exercise lol. That's how much 2022 was a year prioritizing getting healthy and finding fun through sports, rather than growing as a developer. But I can't just chase fun forever ㅠ So I've been thinking about how I can make studying development more enjoyable. One senior developer told me that if you combine your hobbies with development, you naturally end up studying because it's something you're interested in. So I'm thinking about building a climbing-related service as a side project after work. If 2022 was a year of only muscle growth, let's make 2023 a awesome year where I achieve both muscle growth AND growth as a developer!! Let's go!
backingField와 recursive call | Backing Field and Recursive Call
쟈 미
728x90
Backing field
class User(name: String) {
var name: String = name
get() = name
set(value) {name = value}
}
위와 같은 클래스가 있다고 할 때, 코틀린에서 해당 property를 get 혹은 set 할 때 재귀호출이 일어나게 된다.
public fun main(){
println(User("mj").name)
User("mj").name = "jyami"
}
위와 같이 name 프로퍼티를 접근하는 것이 getter를 부르는 것과 같기 때문에 결국get() = this.get() 과 같이, getter를 부르면서 다시 getter를 호출하는 것과 같다.
마찬가지로 name 프로퍼티를 할당하는 것도 setter를 부르는 것과 같아서. set()=this.set("jyami") 다시 setter를 호출하게 된다.
따라서 getter, setter 모두 본인의 필드를 참조하는 경우에는 StackOverflowException 을 발생시키게 된다. 친절하게도 intellij 에서는 recursive call 이라고 안내를 해주고 있다.
추가로 kotlin을 kotlinc를 사용하여 생성된 바이트코드를 보면 어떤 경우에 backing field가 생성되는지를 볼 수 있다. 즉 backing field가 인스턴스 변수로 생성되는 경우는 아래와 같다.
하나이상의 기본 접근자를 사용하는 경우 (getter, setter)
커스텀하게 만든 접근자에서 field 를 사용하는 경우.
data class HttpResponse(val body: String, var headers: Map<String, String>) {
val hasBody: Boolean
get() = body.isNotBlank()
var statusCode: Int = 100
set(value) {
if (value in 100..599) field = value
}
}
body, header는 기본 접근자를 이유로, statusCode는 커스텀 접근자를 이유로 생성되는데, hasBody는 그렇지 않다. (필드로 생성되지 않는다.)
javap -c -p com.kakao.talk.HttpResponse
Compiled from "BackingField.kt"
public final class com.jyami.HttpResponse {
private final java.lang.String body;
private java.util.Map<java.lang.String, java.lang.String> headers;
private int statusCode;
// 함수들의 어셈블러 코드
Backing field
class User(name: String) {
var name: String = name
get() = name
set(value) {name = value}
}
Given a class like the one above, in Kotlin, accessing the property via get or set will cause a recursive call.
public fun main(){
println(User("mj").name)
User("mj").name = "jyami"
}
Since accessing the name property is essentially the same as calling its getter, it ends up being equivalent to get() = this.get() — calling the getter triggers the getter again.
Likewise, assigning to the name property is the same as calling its setter, so set()=this.set("jyami") ends up calling the setter again.
So if both the getter and setter reference their own field, it will throw a StackOverflowException. Thankfully, IntelliJ is kind enough to warn you with a "recursive call" message.
Additionally, if you look at the bytecode generated by kotlinc, you can see when a backing field is actually created. In other words, a backing field is generated as an instance variable in the following cases:
When at least one default accessor is used (getter, setter)
When a custom accessor uses the field identifier.
data class HttpResponse(val body: String, var headers: Map<String, String>) {
val hasBody: Boolean
get() = body.isNotBlank()
var statusCode: Int = 100
set(value) {
if (value in 100..599) field = value
}
}
body and headers get backing fields because they use default accessors, and statusCode gets one because of its custom accessor — but hasBody does not. (It is not generated as a field.)
javap -c -p com.kakao.talk.HttpResponse
Compiled from "BackingField.kt"
public final class com.jyami.HttpResponse {
private final java.lang.String body;
private java.util.Map<java.lang.String, java.lang.String> headers;
private int statusCode;
// Assembler code for functions
Kotlin Void vs Unit vs Nothing | Kotlin Void vs Unit vs Nothing
쟈 미
728x90
Void
자바의 void
java.lang 패키지안에 있는 Void 클래스 : java의 primitive type인 void를 래핑하는 객체이다. (int wrapper인 Integer과 같다고 보면 된다.)
자바에서는 void 말고 Void를 리턴해야하는 경우가 많지 않다. : 제네릭에서 Void를 사용하는 정도의 용례
package java.lang;
/**
* The {@code Void} class is an uninstantiable placeholder class to hold a
* reference to the {@code Class} object representing the Java keyword
* void.
*
* @author unascribed
* @since 1.1
*/
public final
class Void {
/**
* The {@code Class} object representing the pseudo-type corresponding to
* the keyword {@code void}.
*/
@SuppressWarnings("unchecked")
public static final Class<Void> TYPE = (Class<Void>) Class.getPrimitiveClass("void");
/*
* The Void class cannot be instantiated.
*/
private Void() {}
}
Void를 코틀린에서 사용할 때
fun returnTypeAsVoidAttempt1() : Void {
println("Trying with Void return type")
}
이때 컴파일이 되지 않는다.
Error: Kotlin: A 'return' expression required in a function with a block body ('{...}')
그래서 코틀린에서 Void 객체를 만들어서 return 해야하나. 위의 Void 클래스 정의와 같이 private constructor로 인스턴트화가 막혀있다.
따라서 위 경우에는 어쩔수 없이 Void를 nullable로 만들고 Void? null을 리턴해야한다.
fun returnTypeAsVoidAttempt1() : Void? {
println("Trying with Void return type")
return null
}
작동하는 솔루션이 있긴하나. java의 void와 같이 동일한 결과를 낼 수 있는 방법으로 Unit 타입이 있다. (의미 있는 것을 반환하지 않는 함수의 반환 유형)
반환타입이 Unit일 경우네는, return Unit;. return; 모두 선택적으로 작성해도 된다.
fun printHello(name: String?): Unit{
if (name != null) {
println("hello $name")
} else {
println("Hi")
}
}
java에서의 void와 대응한다. 그러나 자바에서 void는 반환 값이 없음을 의미하는 특수 타입이지만, Unit은 class로 정의된 일반타입이다.
Unit은 기본 반환 유형이므로 그리고 return 타입 명시를 안했을 때도 함수가 작동한다.
// Unit.kt
package kotlin
/**
* The type with only one value: the `Unit` object. This type corresponds to the `void` type in Java.
*/
public object Unit {
override fun toString() = "kotlin.Unit"
}
따라서 Unit 타입을 반환하는 함수는 return을 생략해도 암묵적으로 Unit 타입 객체를 리턴한다 (싱글턴 객체이므로 객체 생성은 하지 않는다.)
즉 기원적으로 Void는 Java를 사용할 때 만들어진 클래스, Unit은 Kotlin을 사용할 때 만들어진 클래스인 듯
Nothing
kotlin에서는 throw가 expression 이다. 그래서 이때 throw의 타입이 Nothing 이다.
이 타입은 값이 없으며, 도달할 수 없는 코드 위치를 표한하는데 사용된다. Nothing을 사용하면, 도달할 수 없는 코드의 위치를 컴파일단에서 체크가 가능하다.
fun fail(message: String): Nothing {
throw IllegalArgumentException(message)
}
컴파일단 체크 덕분에 잠재적인 버그와 좋지 않은 코드로부터 확인이 가능하다. 반환 유형이 Nothing인 함수가 호출되면 이 함수 호출 이상으로 실행되지 않고, 컴파일러에서 경고를 내보낸다.
fun invokeANothingOnlyFunction() {
fail("nothing")
println("hello") // Unreachable code
}
또한 Nothing은 type inference (타입추론)에도 사용이 가능하다.
null을 사용하여 초기화된 값일 때의 타입추론
구체적인 타입을 결정하는데 사용할 수 없는 경우에서의 타입추론
val x = null // "type : Nothing?"
val l = listOf(null) // "type : List<Nothing?>"
Nothing은 java에서 대응되는 개념이 없으며, 자바에서는 주로 throw 처리를 할 때 void를 사용했었다.
// Nothing.kt
package kotlin
/**
* Nothing has no instances. You can use Nothing to represent "a value that never exists": for example,
* if a function has the return type of Nothing, it means that it never returns (always throws an exception).
*/
public class Nothing private constructor()
마찬가지로 Nothing도 객체를 생성할 수 없다. (값을 가지지 않는다.)
따라서 Nothing이 값을 가질 수 있는 경우는 Nothing? 에서 null 이 할당되었을 때 뿐이다.
Void
Java's void
The Void class in the java.lang package: It's an object that wraps Java's primitive type void. (Think of it like Integer being the wrapper for int.)
In Java, there aren't many cases where you need to return Void instead of void — it's mostly used in generics.
package java.lang;
/**
* The {@code Void} class is an uninstantiable placeholder class to hold a
* reference to the {@code Class} object representing the Java keyword
* void.
*
* @author unascribed
* @since 1.1
*/
public final
class Void {
/**
* The {@code Class} object representing the pseudo-type corresponding to
* the keyword {@code void}.
*/
@SuppressWarnings("unchecked")
public static final Class<Void> TYPE = (Class<Void>) Class.getPrimitiveClass("void");
/*
* The Void class cannot be instantiated.
*/
private Void() {}
}
Using Void in Kotlin
fun returnTypeAsVoidAttempt1() : Void {
println("Trying with Void return type")
}
This won't compile.
Error: Kotlin: A 'return' expression required in a function with a block body ('{...}')
So should we create a Void object and return it in Kotlin? Well, as you can see from the Void class definition above, instantiation is blocked by a private constructor.
So in this case, you have no choice but to make Void nullable as Void? and return null.
fun returnTypeAsVoidAttempt1() : Void? {
println("Trying with Void return type")
return null
}
While this is a working solution, there's a better way to achieve the same result as Java's void — the Unit type. (It's the return type for functions that don't return anything meaningful.)
When you don't need a return value, you use Unit as the function's return type.
When the return type is Unit, both return Unit; and return; are optional — you can write either or omit them entirely.
fun printHello(name: String?): Unit{
if (name != null) {
println("hello $name")
} else {
println("Hi")
}
}
It corresponds to void in Java. However, while void in Java is a special type meaning "no return value," Unit is a regular type defined as a class.
Since Unit is the default return type, functions work even when you don't explicitly specify a return type.
// Unit.kt
package kotlin
/**
* The type with only one value: the `Unit` object. This type corresponds to the `void` type in Java.
*/
public object Unit {
override fun toString() = "kotlin.Unit"
}
So a function that returns Unit implicitly returns the Unit object even if you omit the return statement. (Since it's a singleton object, no new object is created.)
In other words, it seems like Void is a class that originated from Java, while Unit is a class that originated from Kotlin.
Nothing
In Kotlin, throw is an expression. And the type of that throw expression is Nothing.
This type has no value and is used to mark code locations that can never be reached. By using Nothing, unreachable code locations can be checked at compile time.
fun fail(message: String): Nothing {
throw IllegalArgumentException(message)
}
Thanks to compile-time checks, you can catch potential bugs and bad code. When a function with a return type of Nothing is called, execution never continues beyond that function call, and the compiler emits a warning.
fun invokeANothingOnlyFunction() {
fail("nothing")
println("hello") // Unreachable code
}
Nothing can also be used in type inference.
Type inference for values initialized with null
Type inference when a concrete type cannot be determined
val x = null // "type : Nothing?"
val l = listOf(null) // "type : List<Nothing?>"
Nothing has no corresponding concept in Java. In Java, void was typically used when handling throw.
// Nothing.kt
package kotlin
/**
* Nothing has no instances. You can use Nothing to represent "a value that never exists": for example,
* if a function has the return type of Nothing, it means that it never returns (always throws an exception).
*/
public class Nothing private constructor()
Likewise, Nothing cannot be instantiated either. (It holds no value.)
Therefore, the only case where Nothing can hold a value is when null is assigned to Nothing?.



















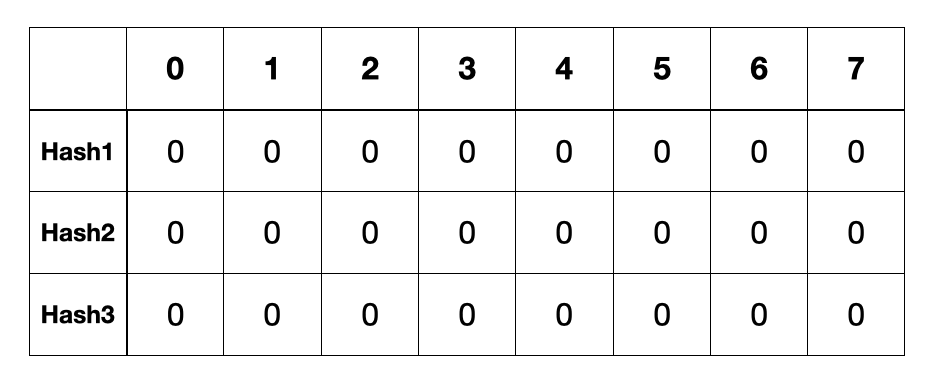















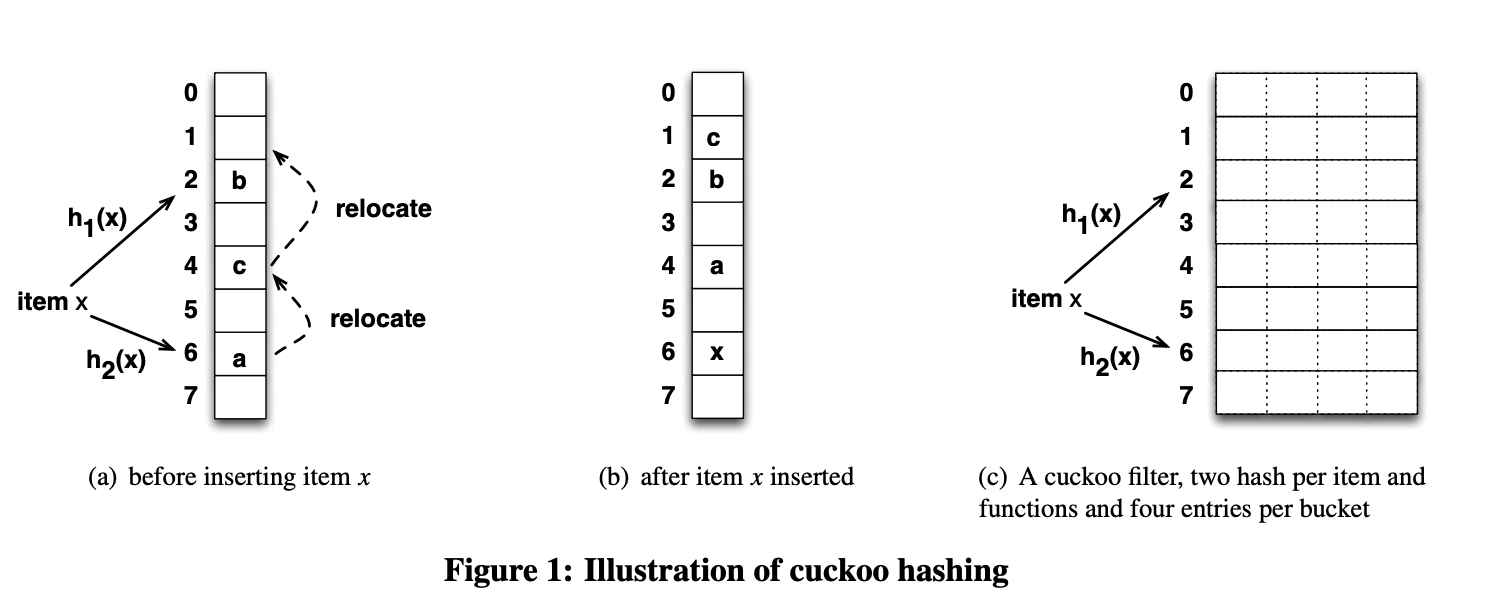
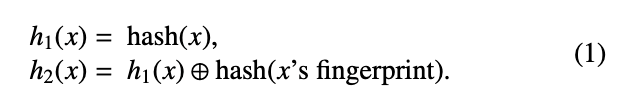
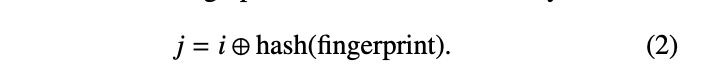

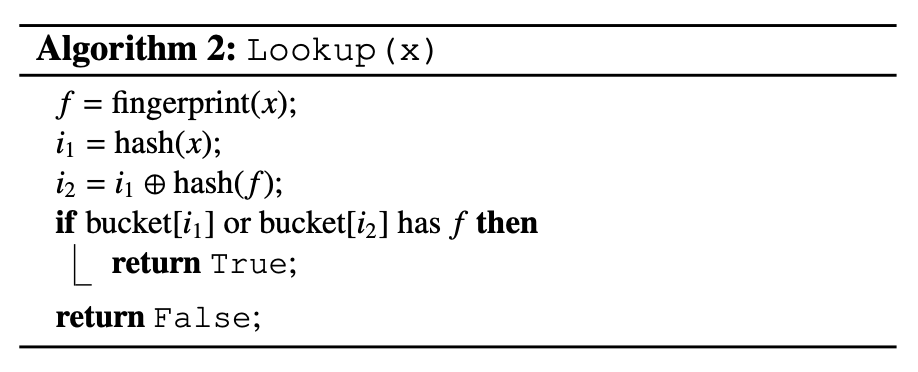


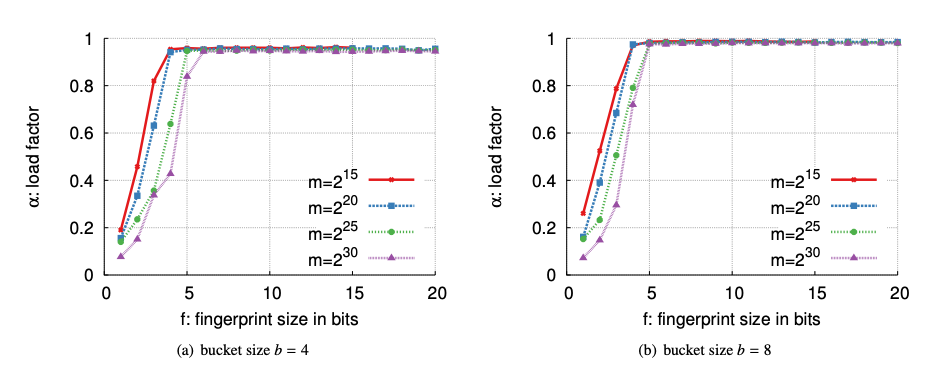


















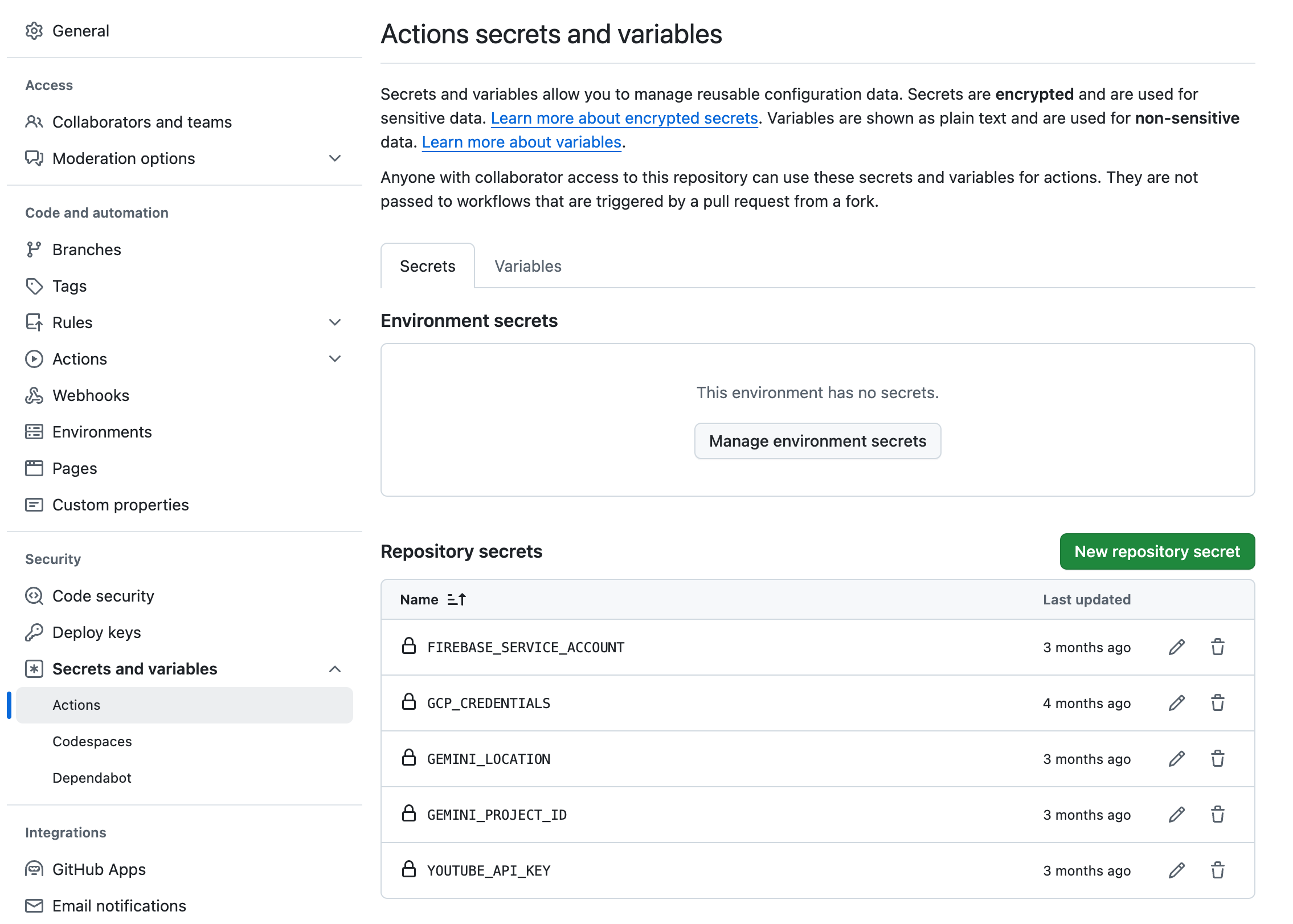





















































댓글
Comments